Visible Query Answering (VQA) is a helpful machine studying (ML) process that requires a mannequin to reply a visible query about a picture. What makes it difficult is its multi-task and open-ended nature; it includes fixing a number of technical analysis questions in laptop imaginative and prescient and pure language understanding concurrently. But, progress on this process would allow a variety of purposes, from aiding the blind and the visually-impaired or speaking with robots to enhancing the consumer’s visible expertise with exterior data.
Efficient and strong VQA techniques can’t exist with out high-quality, semantically and stylistically numerous large-scale coaching knowledge of image-question-answer triplets. However, creating such knowledge is time consuming and onerous. Maybe unsurprisingly, the VQA neighborhood has centered extra on subtle mannequin improvement fairly than scalable knowledge creation.
In “All You Might Want for VQA are Picture Captions,” revealed at NAACL 2022, we discover VQA knowledge era by proposing “Visible Query Era with Query Answering Validation” (VQ2A), a pipeline that works by rewriting a declarative caption into a number of interrogative question-answer pairs. Extra particularly, we leverage two current belongings — (i) large-scale image-text knowledge and (ii) large-capacity neural text-to-text fashions — to attain automated VQA knowledge era. As the sphere has progressed, the analysis neighborhood has been making these belongings bigger and stronger in isolation (for basic functions akin to studying text-only or image-text representations); collectively, they will obtain extra and we adapt them for VQA knowledge creation functions. We discover our method can generate question-answer pairs with excessive precision and that this knowledge can efficiently be used for coaching VQA fashions to enhance efficiency.
 |
 |
 |
| The VQ2A method permits VQA knowledge era at scale from picture captions by rewriting every caption into a number of question-answer pairs. |
VQ2A Overview
Step one of the VQ2A method is to use heuristics based mostly on named entity recognition, part-of-speech tagging and manually outlined guidelines to generate reply candidates from the picture caption. These generated candidates are small items of knowledge which may be related topics about which to ask questions. We additionally add to this checklist two default solutions, “sure” and “no”, which permit us to generate Boolean questions.
Then, we use a T5 mannequin that was fine-tuned to generate questions for the candidate, leading to [question, candidate answer] pairs. We then filter for the very best high quality pairs utilizing one other T5 mannequin (fine-tuned to reply questions) by asking it to reply the query based mostly on the caption. was . That’s, we examine the candidate reply to the output of this mannequin and if the 2 solutions are related sufficient, we outline this query as prime quality and preserve it. In any other case, we filter it out.
The concept of utilizing each query answering and query era fashions to test one another for his or her round-trip consistency has been beforehand explored in different contexts. As an example, Q2 makes use of this concept to guage factual consistency in knowledge-grounded dialogues. Ultimately, the VQ2A method, as illustrated beneath, can generate a lot of [image, question, answer] triplets which are high-quality sufficient for use as VQA coaching knowledge.
 |
| VQ2A consists of three fundamental steps: (i) candidate reply extraction, (ii) query era, (iii) query answering and reply validation. |
Outcomes
Two examples of our generated VQA knowledge are proven beneath, one based mostly on human-written COCO Captions (COCO) and the opposite on automatically-collected Conceptual Captions (CC3M), which we name VQ2A-COCO and VQ2A-CC3M, respectively. We spotlight the number of query varieties and types, that are crucial for VQA. General, the cleaner the captions (i.e., the extra intently associated they’re to their paired picture), the extra correct the generated triplets. Primarily based on 800 samples every, 87.3% of VQ2A-COCO and 66.0% VQ2A-CC3M are discovered by human raters to be legitimate, suggesting that our method can generate question-answer pairs with excessive precision.
 |
 |
| Generated question-answer pairs based mostly on COCO Captions (high) and Conceptual Captions (backside). Gray highlighting denotes questions that do not seem in VQAv2, whereas inexperienced highlighting denotes people who do, indicating that our method is able to producing novel questions that an current VQA dataset doesn’t have. |
Lastly, we consider our generated knowledge through the use of it to coach VQA fashions (highlights proven beneath). We observe that our automatically-generated VQA knowledge is aggressive with manually-annotated goal VQA knowledge. First, our VQA fashions obtain excessive efficiency on course benchmarks “out-of-the-box”, when skilled solely on our generated knowledge (gentle blue and light-weight purple vs. yellow). As soon as fine-tuned on course knowledge, our VQA fashions outperform target-only coaching barely on large-scale benchmarks like VQAv2 and GQA, however considerably on the small, knowledge-seeking OK-VQA (darkish blue/purple vs. gentle blue/purple).
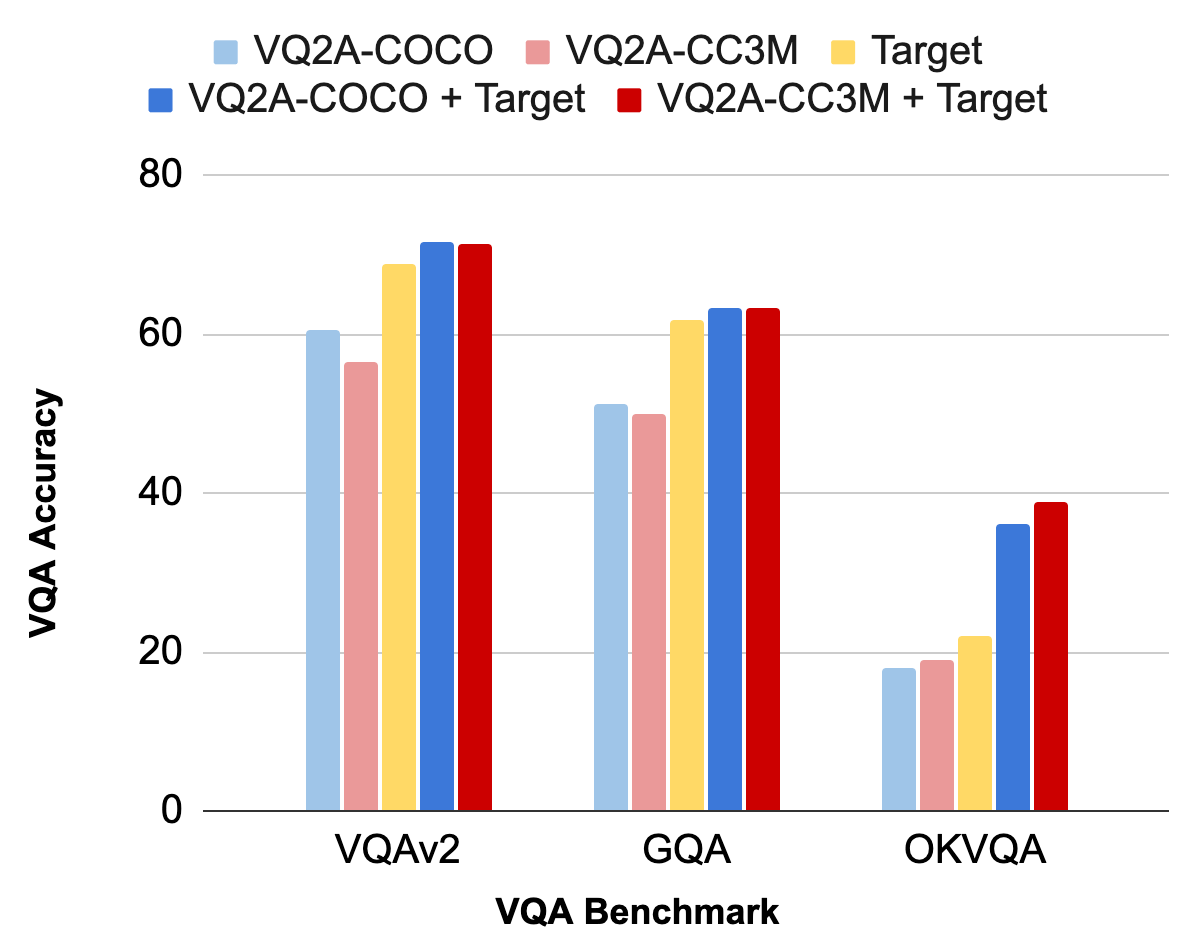 |
| VQA accuracy on fashionable benchmark datasets. |
Conclusion
All we might have for VQA are picture captions! This work demonstrates that it’s attainable to routinely generate high-quality VQA knowledge at scale, serving as an important constructing block for VQA and vision-and-language fashions typically (e.g., ALIGN, CoCa). We hope that our work conjures up different work on data-centric VQA.
Acknowledgments
We thank Roee Aharoni, Idan Szpektor, and Radu Soricut for his or her suggestions on this blogpost. We additionally thank our co-authors: Xi Chen, Nan Ding, Idan Szpektor, and Radu Soricut. We acknowledge contributions from Or Honovich, Hagai Taitelbaum, Roee Aharoni, Sebastian Goodman, Piyush Sharma, Nassim Oufattole, Gal Elidan, Sasha Goldshtein, and Avinatan Hassidim. Lastly, we thank the authors of Q2, whose pipeline strongly influences this work.




