
The launch of stability.ai’s Steady Diffusion latent diffusion picture synthesis mannequin a few weeks in the past could also be probably the most vital technological disclosures since DeCSS in 1999; it’s definitely the most important occasion in AI-generated imagery for the reason that 2017 deepfakes code was copied over to GitHub and forked into what would turn into DeepFaceLab and FaceSwap, in addition to the real-time streaming deepfake software program DeepFaceLive.
At a stroke, person frustration over the content material restrictions in DALL-E 2’s picture synthesis API had been swept apart, because it transpired that Steady Diffusion’s NSFW filter may very well be disabled by altering a sole line of code. Porn-centric Steady Diffusion Reddits sprung up virtually instantly, and had been as shortly lower down, whereas the developer and person camp divided on Discord into the official and NSFW communities, and Twitter started to refill with fantastical Steady Diffusion creations.
For the time being, every day appears to convey some superb innovation from the builders who’ve adopted the system, with plugins and third-party adjuncts being rapidly written for Krita, Photoshop, Cinema4D, Blender, and plenty of different software platforms.
Within the meantime, promptcraft – the now- skilled artwork of ‘AI whispering’, which can find yourself being the shortest profession possibility since ‘Filofax binder’ – is already turning into commercialized, whereas early monetization of Steady Diffusion is happening on the Patreon degree, with the knowledge of extra refined choices to return, for these unwilling to navigate Conda-based installs of the supply code, or the proscriptive NSFW filters of web-based implementations.
The tempo of growth and free sense of exploration from customers is continuing at such a dizzying velocity that it’s troublesome to see very far forward. Primarily, we don’t know precisely what we’re coping with but, or what all of the limitation or prospects is likely to be.
Nonetheless, let’s check out three of what is likely to be essentially the most attention-grabbing and difficult hurdles for the rapidly-formed and rapidly-growing Steady Diffusion neighborhood to face and, hopefully, overcome.
1: Optimizing Tile-Primarily based Pipelines
Introduced with restricted {hardware} sources and laborious limits on the decision of coaching photographs, it appears doubtless that builders will discover workarounds to enhance each the standard and the decision of Steady Diffusion output. Lots of these initiatives are set to contain exploiting the constraints of the system, equivalent to its native decision of a mere 512×512 pixels.
As is all the time the case with laptop imaginative and prescient and picture synthesis initiatives, Steady Diffusion was educated on sq. ratio photographs, on this case resampled to 512×512, in order that the supply photographs may very well be regularized and capable of match into the constraints of the GPUs that educated the mannequin.
Subsequently Steady Diffusion ‘thinks’ (if it thinks in any respect) in 512×512 phrases, and positively in sq. phrases. Many customers at the moment probing the boundaries of the system report that Steady Diffusion produces essentially the most dependable and least glitchy outcomes at this quite constrained facet ratio (see ‘addressing extremities’ under).
Although varied implementations characteristic upscaling through RealESRGAN (and might repair poorly rendered faces through GFPGAN) a number of customers are at the moment growing strategies to separate up photographs into 512x512px sections and sew the photographs collectively to type bigger composite works.

This 1024×576 render, a decision typically not possible in a single Steady Diffusion render, was created by copying and pasting the eye.py Python file from the DoggettX fork of Steady Diffusion (a model which implements tile-based upscaling) into one other fork. Supply: https://previous.reddit.com/r/StableDiffusion/feedback/x6yeam/1024x576_with_6gb_nice/
Although some initiatives of this type are utilizing unique code or different libraries, the txt2imghd port of GOBIG (a mode within the VRAM-hungry ProgRockDiffusion) is about to supply this performance to the principle department quickly. Whereas txt2imghd is a devoted port of GOBIG, different efforts from neighborhood builders includes totally different implementations of GOBIG.

A conveniently summary picture within the unique 512x512px render (left and second from left); upscaled by ESGRAN, which is now kind of native throughout all Steady Diffusion distributions; and given ‘particular consideration’ through an implementation of GOBIG, producing element that, no less than throughout the confines of the picture part, appear better-upscaled. Source: https://previous.reddit.com/r/StableDiffusion/feedback/x72460/stable_diffusion_gobig_txt2imghd_easy_mode_colab/
The form of summary instance featured above has many ‘little kingdoms’ of element that go well with this solipsistic strategy to upscaling, however which can require more difficult code-driven options with a view to produce non-repetitive, cohesive upscaling that doesn’t look prefer it was assembled from many elements. Not least, within the case of human faces, the place we’re unusually attuned to aberrations or ‘jarring’ artifacts. Subsequently faces could finally want a devoted answer.
Steady Diffusion at the moment has no mechanism for focusing consideration on the face throughout a render in the identical means that people prioritize facial data. Although some builders within the Discord communities are contemplating strategies to implement this type of ‘enhanced consideration’, it’s at the moment a lot simpler to manually (and, finally, robotically) improve the face after the preliminary render has taken place.
A human face has an inner and full semantic logic that received’t be present in a ’tile’ of the underside nook of (as an example) a constructing, and due to this fact it’s at the moment attainable to very successfully ‘zoom in’ and re-render a ‘sketchy’ face in Steady Diffusion output.

Left, Steady Diffusion’s preliminary effort with the immediate ‘Full-length colour photograph of Christina Hendricks coming into a crowded place, carrying a raincoat; Canon50, eye contact, excessive element, excessive facial element’. Proper, an improved face obtained by feeding the blurred and sketchy face from the primary render again into the complete consideration of Steady Diffusion utilizing Img2Img (see animated photographs under).
Within the absence of a devoted Textual Inversion answer (see under), this can solely work for superstar photographs the place the individual in query is already well-represented within the LAION information subsets that educated Steady Diffusion. Subsequently it would work on the likes of Tom Cruise, Brad Pitt, Jennifer Lawrence, and a restricted vary of real media luminaries which can be current in nice numbers of photographs within the supply information.
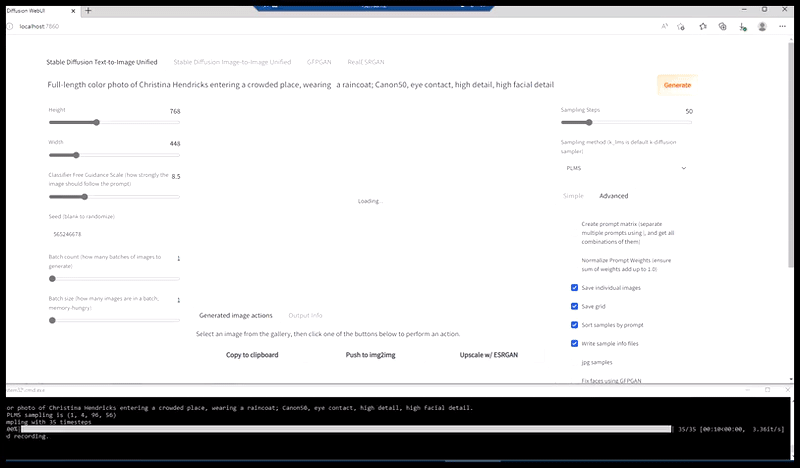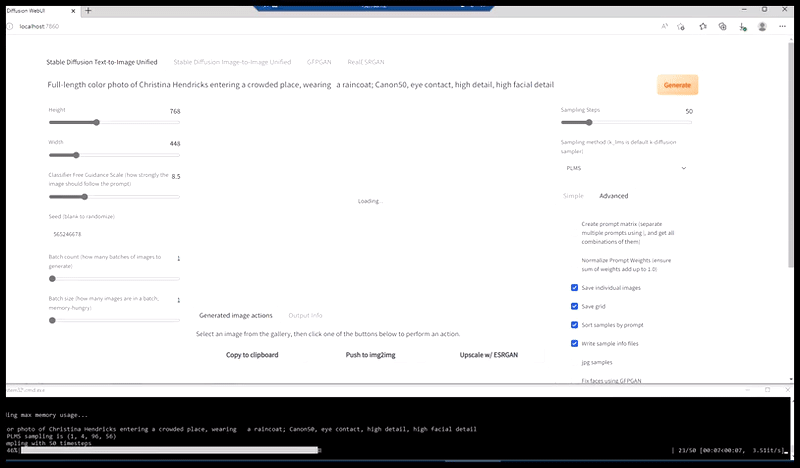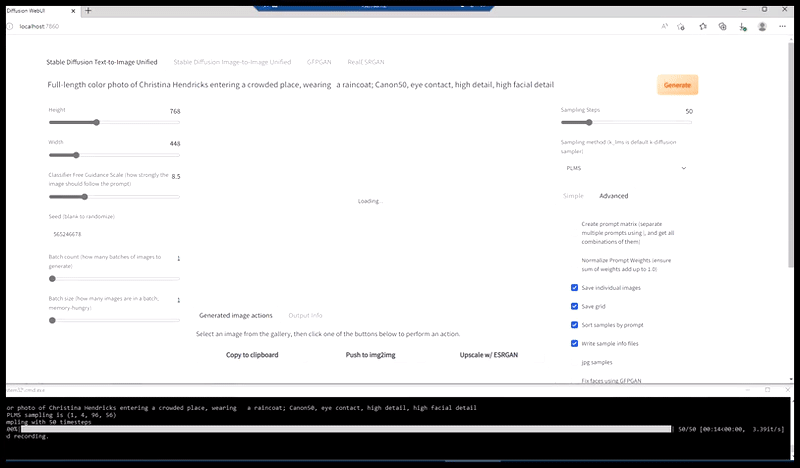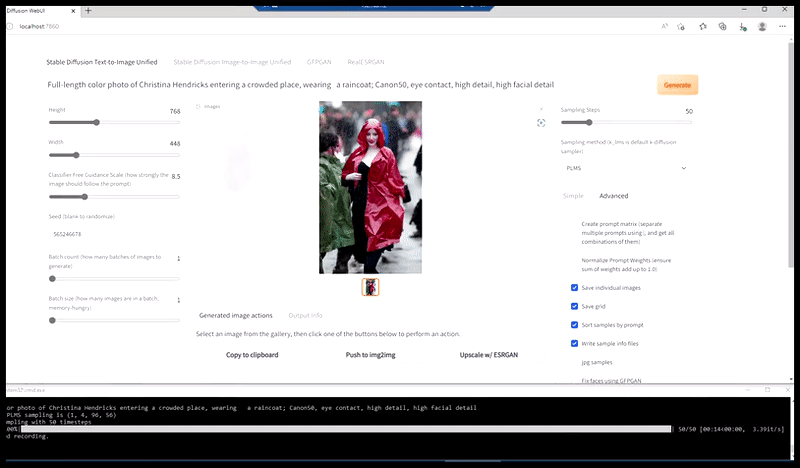
Producing a believable press image with the immediate ‘Full-length colour photograph of Christina Hendricks coming into a crowded place, carrying a raincoat; Canon50, eye contact, excessive element, excessive facial element’.
For celebrities with lengthy and enduring careers, Steady Diffusion will often generate a picture of the individual at a latest (i.e. older) age, and it will likely be vital so as to add immediate adjuncts equivalent to ‘younger’ or ‘within the yr [YEAR]’ with a view to produce younger-looking photographs.

With a distinguished, much-photographed and constant profession spanning practically 40 years, actress Jennifer Connelly is one among a handful of celebrities in LAION that permit Steady Diffusion to signify a variety of ages. Supply: prepack Steady Diffusion, native, v1.4 checkpoint; age-related prompts.
That is largely due to the proliferation of digital (quite than costly, emulsion-based) press pictures from the mid-2000s on, and the later development in quantity of picture output resulting from elevated broadband speeds.
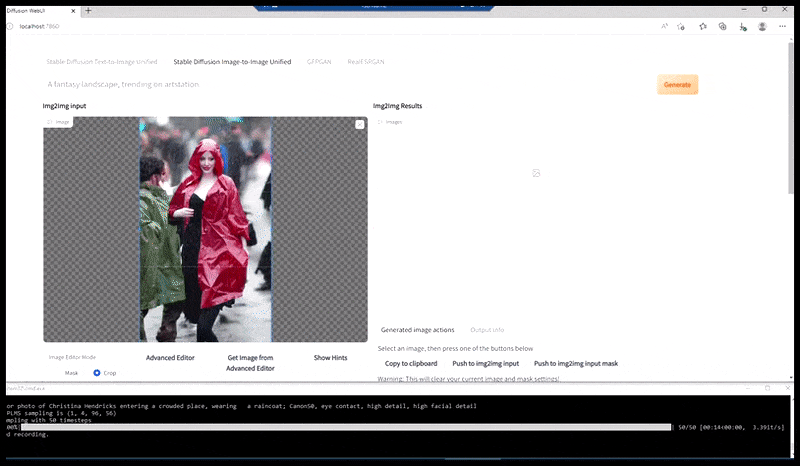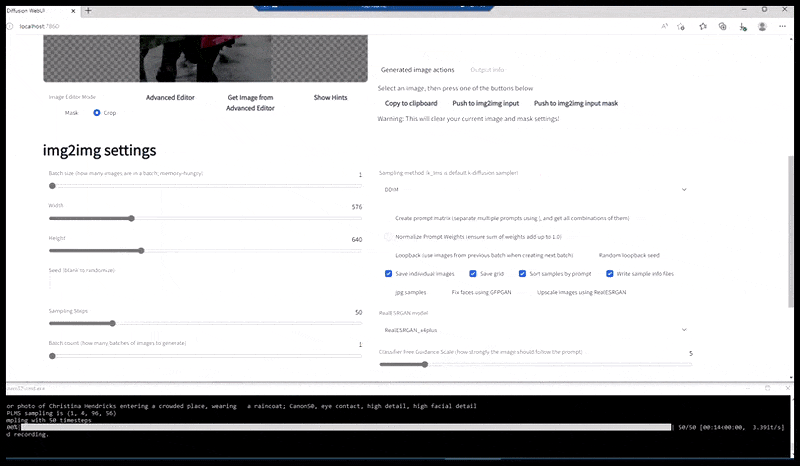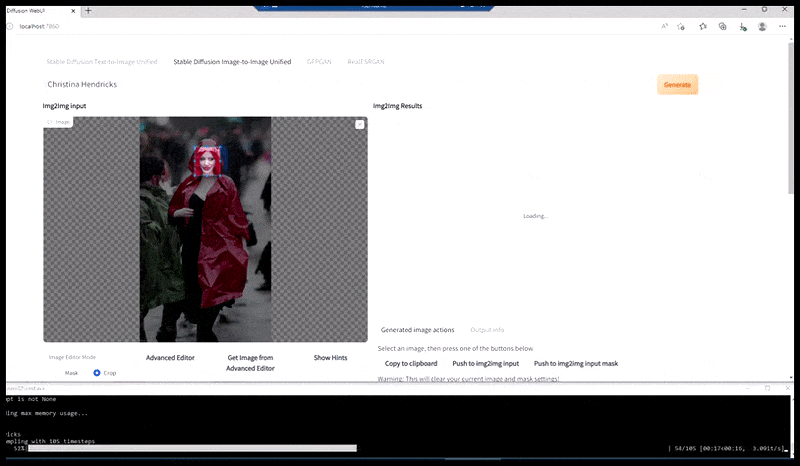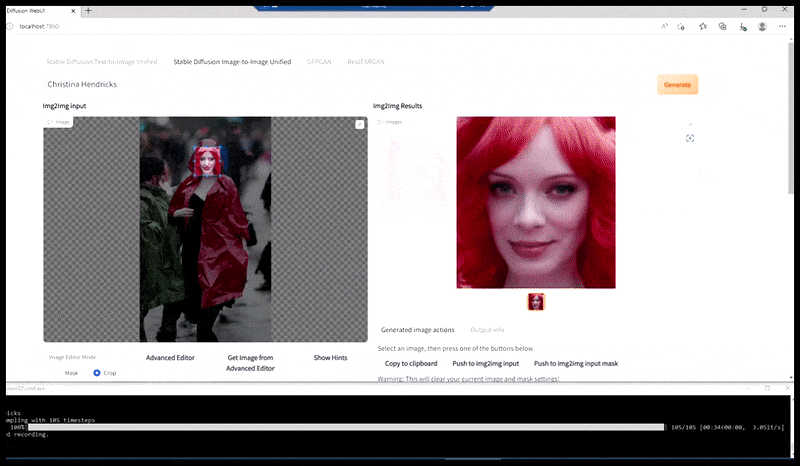
The rendered picture is handed by to Img2Img in Steady Diffusion, the place a ‘focus space’ is chosen, and a brand new, maximum-size render is made solely of that space, permitting Steady Diffusion to pay attention all accessible sources on recreating the face.
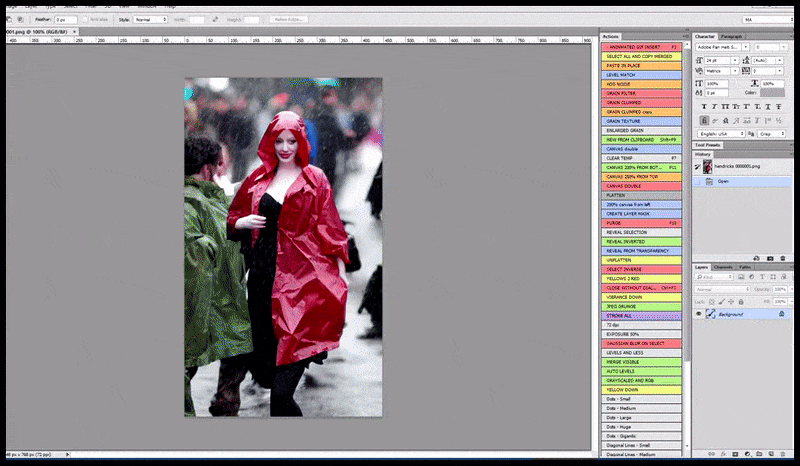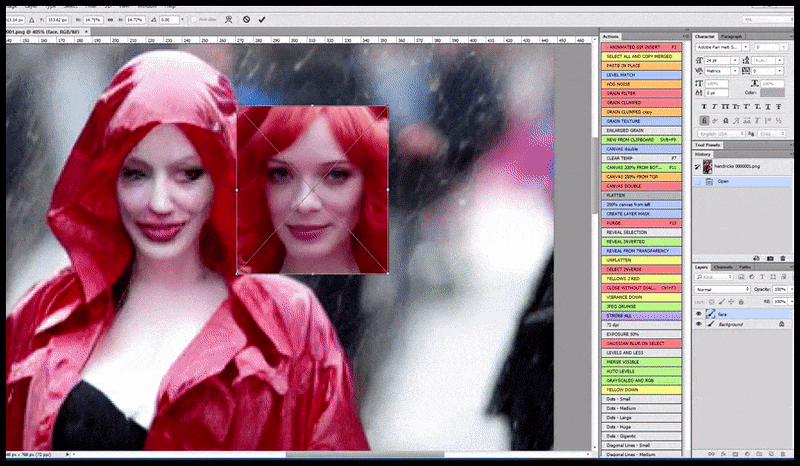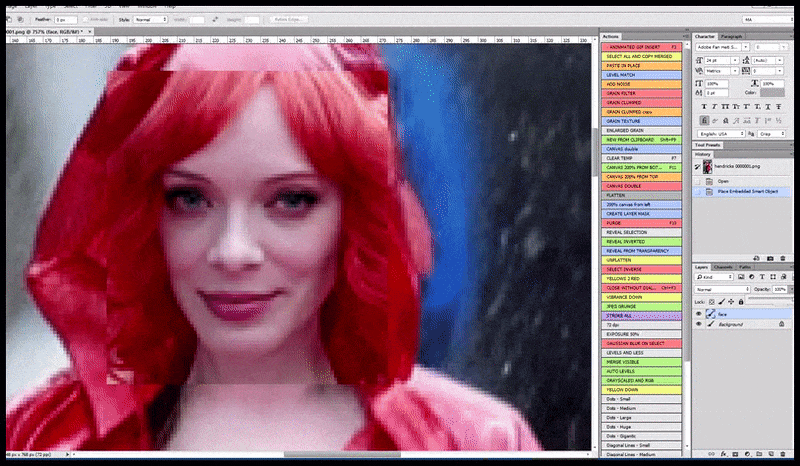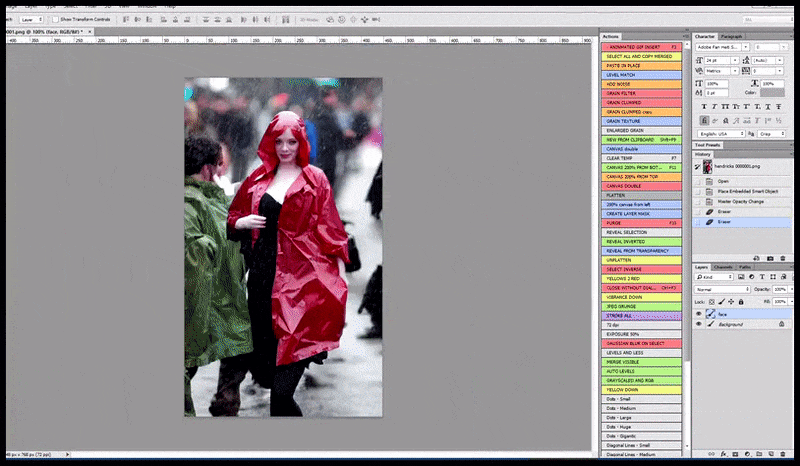
Compositing the ‘excessive consideration’ face again into the unique render. In addition to faces, this course of will solely work with entities which have a possible recognized, cohesive and integral look, equivalent to a portion of the unique photograph that has a definite object, equivalent to a watch or a automotive. Upscaling a piece of – as an example – a wall goes to result in a really strange-looking reassembled wall, as a result of the tile renders had no wider context for this ‘jigsaw piece’ as they had been rendering.
Some celebrities within the database come ‘pre-frozen’ in time, both as a result of they died early (equivalent to Marilyn Monroe), or rose to solely fleeting mainstream prominence, producing a excessive quantity of photographs in a restricted time period. Polling Steady Diffusion arguably gives a form of ‘present’ recognition index for contemporary and older stars. For some older and present celebrities, there aren’t sufficient photographs within the supply information to acquire an excellent likeness, whereas the enduring recognition of explicit long-dead or in any other case pale stars be sure that their affordable likeness may be obtained from the system.

Steady Diffusion renders shortly reveal which well-known faces are well-represented within the coaching information. Regardless of her monumental recognition as an older teenager on the time of writing, Millie Bobby Brown was youthful and fewer well-known when the LAION supply datasets had been scraped from the online, making a high-quality likeness with Steady Diffusion problematic in the intervening time.
The place the information is accessible, tile-based up-res options in Steady Diffusion might go additional than homing in on the face: they might doubtlessly allow much more correct and detailed faces by breaking the facial options down and turning the whole drive of native GPU sources on salient options individually, previous to reassembly – a course of which is at the moment, once more, guide.

This isn’t restricted to faces, however it’s restricted to elements of objects which can be no less than as predictably-placed within the wider context of the host object, and which conform to high-level embeddings that one might moderately look forward to finding in a hyperscale dataset.
The true restrict is the quantity of accessible reference information within the dataset, as a result of, finally, deeply-iterated element will turn into completely ‘hallucinated’ (i.e. fictitious) and fewer genuine.
Such high-level granular enlargements work within the case of Jennifer Connelly, as a result of she is well-represented throughout a variety of ages in LAION-aesthetics (the first subset of LAION 5B that Steady Diffusion makes use of), and customarily throughout LAION; in lots of different instances, accuracy would endure from lack of knowledge, necessitating both fine-tuning (extra coaching, see ‘Customization’ under) or Textual Inversion (see under).
Tiles are a robust and comparatively low-cost means for Steady Diffusion to be enabled to supply hi-res output, however algorithmic tiled upscaling of this type, if it lacks some form of broader, higher-level consideration mechanism, could fall in need of the hoped-for requirements throughout a variety of content material sorts.
2: Addressing Points with Human Limbs
Steady Diffusion doesn’t dwell as much as its title when depicting the complexity of human extremities. Palms can multiply randomly, fingers coalesce, third legs seem unbidden, and present limbs vanish with out hint. In its protection, Steady Diffusion shares the issue with its stablemates, and most definitely with DALL-E 2.

Non-edited outcomes from DALL-E 2 and Steady Diffusion (1.4) on the finish of August 2022, each exhibiting points with limbs. Immediate is ‘A lady embracing a person’
Steady Diffusion followers hoping that the forthcoming 1.5 checkpoint (a extra intensely educated model of the mannequin, with improved parameters) would remedy the limb confusion are prone to be upset. The brand new mannequin, which will likely be launched in about two weeks’ time, is at the moment being premiered on the business stability.ai portal DreamStudio, which makes use of 1.5 by default, and the place customers can evaluate the brand new output with renders from their native or different 1.4 programs:

Supply: Native 1.4 prepack and https://beta.dreamstudio.ai/

Supply: Native 1.4 prepack and https://beta.dreamstudio.ai/

Supply: Native 1.4 prepack and https://beta.dreamstudio.ai/
As is usually the case, information high quality might effectively be the first contributing trigger.
The open supply databases that gas picture synthesis programs equivalent to Steady Diffusion and DALL-E 2 are capable of present many labels for each particular person people and inter-human motion. These labels get trained-in symbiotically with their related photographs, or segments of photographs.

Steady Diffusion customers can discover the ideas educated into the mannequin by querying the LAION-aesthetics dataset, a subset of the bigger LAION 5B dataset, which powers the system. The photographs are ordered not by their alphabetical labels, however by their ‘aesthetic rating’. Supply: https://rom1504.github.io/clip-retrieval/
A good hierarchy of Particular person labels and courses contributing to the depiction of a human arm could be one thing like physique>arm>hand>fingers>[sub digits + thumb]> [digit segments]>Fingernails.

Granular semantic segmentation of the elements of a hand. Even this unusually detailed deconstruction leaves every ‘finger’ as a sole entity, not accounting for the three sections of a finger and the 2 sections of a thumb. Supply: https://athitsos.utasites.cloud/publications/rezaei_petra2021.pdf
In actuality, the supply photographs are unlikely to be so persistently annotated throughout the whole dataset, and unsupervised labeling algorithms will most likely cease on the larger degree of – as an example – ‘hand’, and depart the inside pixels (which technically comprise ‘finger’ data) as an unlabeled mass of pixels from which options will likely be arbitrarily derived, and which can manifest in later renders as a jarring factor.

The way it ought to be (higher proper, if not upper-cut), and the way it tends to be (decrease proper), resulting from restricted sources for labeling, or architectural exploitation of such labels in the event that they do exist within the dataset.
Thus, if a latent diffusion mannequin will get so far as rendering an arm, it’s virtually definitely going to no less than have a go at rendering a hand on the finish of that arm, as a result of arm>hand is the minimal requisite hierarchy, pretty excessive up in what the structure is aware of about ‘human anatomy’.
After that, ‘fingers’ stands out as the smallest grouping, regardless that there are 14 additional finger/thumb sub-parts to contemplate when depicting human fingers.
If this idea holds, there isn’t a actual treatment, because of the sector-wide lack of funds for guide annotation, and the shortage of adequately efficient algorithms that might automate labeling whereas producing low error charges. In impact, the mannequin could at the moment be counting on human anatomical consistency to paper over the shortcomings of the dataset it was educated on.
One attainable purpose why it can’t depend on this, just lately proposed on the Steady Diffusion Discord, is that the mannequin might turn into confused in regards to the appropriate variety of fingers a (practical) human hand ought to have as a result of the LAION-derived database powering it options cartoon characters which will have fewer fingers (which is in itself a labor-saving shortcut).

Two of the potential culprits in ‘lacking finger’ syndrome in Steady Diffusion and comparable fashions. Beneath, examples of cartoon fingers from the LAION-aesthetics dataset powering Steady Diffusion. Supply: https://www.youtube.com/watch?v=0QZFQ3gbd6I
If that is true, then the one apparent answer is to retrain the mannequin, excluding non-realistic human-based content material, guaranteeing that real instances of omission (i.e. amputees) are suitably labeled as exceptions. From a knowledge curation level alone, this might be fairly a problem, significantly for resource-starved neighborhood efforts.
The second strategy could be to use filters which exclude such content material (i.e. ‘hand with three/5 fingers’) from manifesting at render time, in a lot the identical means that OpenAI has, to a sure extent, filtered GPT-3 and DALL-E 2, in order that their output may very well be regulated without having to retrain the supply fashions.

For Steady Diffusion, the semantic distinction between digits and even limbs can turn into horrifically blurred, bringing to thoughts the Nineteen Eighties ‘physique horror’ strand of horror films from the likes of David Cronenberg. Supply: https://previous.reddit.com/r/StableDiffusion/feedback/x6htf6/a_study_of_stable_diffusions_strange_relationship/
Nevertheless, once more, this might require labels that will not exist throughout all of the affected photographs, leaving us with the identical logistical and budgetary problem.
It may very well be argued that there are two remaining roads ahead: throwing extra information on the drawback, and making use of third-party interpretive programs that may intervene when bodily goofs of the kind described listed below are being introduced to the tip person (on the very least, the latter would give OpenAI a technique to supply refunds for ‘physique horror’ renders, if the corporate was motivated to take action).
3: Customization
One of the thrilling prospects for the way forward for Steady Diffusion is the prospect of customers or organizations growing revised programs; modifications that permit content material exterior of the pretrained LAION sphere to be built-in into the system – ideally with out the ungovernable expense of coaching the whole mannequin over once more, or the chance entailed when coaching in a big quantity of novel photographs to an present, mature and succesful mannequin.
By analogy: if two less-gifted college students be part of a complicated class of thirty college students, they’ll both assimilate and catch up, or fail as outliers; in both case, the category common efficiency will most likely not be affected. If 15 less-gifted college students be part of, nonetheless, the grade curve for the whole class is prone to endure.
Likewise, the synergistic and pretty delicate community of relationships which can be constructed up over sustained and costly mannequin coaching may be compromised, in some instances successfully destroyed, by extreme new information, decreasing the output high quality for the mannequin throughout the board.
The case for doing that is primarily the place your curiosity lies in fully hi-jacking the mannequin’s conceptual understanding of relationships and issues, and appropriating it for the unique manufacturing of content material that’s much like the extra materials that you simply added.
Thus, coaching 500,000 Simpsons frames into an present Steady Diffusion checkpoint is probably going, finally, to get you a greater Simpsons simulator than the unique construct might have supplied, presuming that sufficient broad semantic relationships survive the method (i.e. Homer Simpson consuming a hotdog, which can require materials about hot-dogs that was not in your extra materials, however did exist already within the checkpoint), and presuming that you simply don’t need to out of the blue change from Simpsons content material to creating fabulous panorama by Greg Rutkowski – as a result of your post-trained mannequin has had its consideration massively diverted, and received’t be nearly as good at doing that form of factor because it was once.
One notable instance of that is waifu-diffusion, which has efficiently post-trained 56,000 anime photographs right into a accomplished and educated Steady Diffusion checkpoint. It’s a troublesome prospect for a hobbyist, although, for the reason that mannequin requires an eye-watering minimal of 30GB of VRAM, far past what’s prone to be accessible on the shopper tier in NVIDIA’s forthcoming 40XX collection releases.

The coaching of customized content material into Steady Diffusion through waifu-diffusion: the mannequin took two weeks of post-training with a view to output this degree of illustration. The six photographs on the left present the progress of the mannequin, as coaching proceeded, in making subject-coherent output based mostly on the brand new coaching information. Supply: https://gigazine.internet/gsc_news/en/20220121-how-waifu-labs-create/
Quite a lot of effort may very well be expended on such ‘forks’ of Steady Diffusion checkpoints, solely to be stymied by technical debt. Builders on the official Discord have already indicated that later checkpoint releases should not essentially going to be backward-compatible, even with immediate logic which will have labored with a earlier model, since their main curiosity is in acquiring the very best mannequin attainable, quite than supporting legacy functions and processes.
Subsequently an organization or person who decides to department off a checkpoint right into a business product successfully has no means again; their model of the mannequin is, at that time, a ‘laborious fork’, and received’t have the ability to attract upstream advantages from later releases from stability.ai – which is kind of a dedication.
The present, and better hope for personalization of Steady Diffusion is Textual Inversion, the place the person trains in a small handful of CLIP-aligned photographs.

A collaboration between Tel Aviv College and NVIDIA, textual inversion permits for the training-in of discrete and novel entities, with out destroying the capabilities of the supply mannequin. Supply: https://textual-inversion.github.io/
The first obvious limitation of textual inversion is {that a} very low variety of photographs are advisable – as few as 5. This successfully produces a restricted entity that could be extra helpful for type switch duties quite than the insertion of photorealistic objects.
Nonetheless, experiments are at the moment happening throughout the varied Steady Diffusion Discords that use a lot larger numbers of coaching photographs, and it stays to be seen how productive the strategy would possibly show. Once more, the method requires a substantial amount of VRAM, time, and endurance.
Resulting from these limiting components, we could have to attend some time to see a number of the extra refined textual inversion experiments from Steady Diffusion lovers – and whether or not or not this strategy can ‘put you within the image’ in a fashion that appears higher than a Photoshop cut-and-paste, whereas retaining the astounding performance of the official checkpoints.
First revealed sixth September 2022.





