
AWS Glue is a serverless knowledge integration service that makes it easy to find, put together, transfer, and combine knowledge from a number of sources for analytics, machine studying (ML), and utility improvement. Immediately, AWS Glue processes buyer jobs utilizing both Apache Spark’s distributed processing engine for giant workloads or Python’s single-node processing engine for smaller workloads. Prospects like Python for its ease of use and wealthy assortment of built-in data-processing libraries however may discover it troublesome for patrons to scale Python past a single compute node. This limitation makes it troublesome for patrons to course of massive datasets. Prospects desire a answer that enables them to proceed utilizing acquainted Python instruments and AWS Glue jobs on knowledge units of all sizes, even these that may’t match on a single occasion.
We’re glad to announce the discharge of a brand new AWS Glue job sort: Ray. Ray is an open-source unified compute framework that makes it easy to scale AI and Python workloads. Ray began as an open-source undertaking at RISELab in UC Berkeley. In case your utility is written in Python, you possibly can scale it with Ray in a distributed cluster in a multi-node atmosphere. Ray is Python native and you may mix it with the AWS SDK for pandas to arrange, combine and remodel your knowledge for working your knowledge analytics and ML workloads together. You need to use AWS Glue for Ray with Glue Studio Notebooks, SageMaker Studio Pocket book, or an area pocket book or IDE of your selection.
This submit offers an introduction to AWS Glue for Ray and reveals you begin utilizing Ray to distribute your Python workloads.
What’s AWS Glue for Ray?
Prospects just like the serverless expertise and quick begin time provided by AWS Glue. With the introduction of Ray, we have now ensured that you simply get the identical expertise. We now have additionally ensured that you need to use the AWS Glue job and AWS Glue interactive session primitives to entry the Ray engine. AWS Glue jobs are fire-and-forget techniques the place buyer submit their Ray code to the AWS Glue jobs API and AWS Glue routinely provisions the required compute assets and runs the job. AWS Glue interactive session APIs enable interactive exploration of the information for the aim of job improvement. Whatever the possibility used, you’re solely billed during the compute used. With AWS Glue for Ray, we’re additionally introducing a brand new Graviton2 based mostly employee (Z.2x) which affords 8 digital CPUs and 64 GB of RAM.
AWS Glue for Ray consists of two main elements:
- Ray Core – The distributed computing framework
- Ray Dataset – The distributed knowledge framework based mostly on Apache Arrow
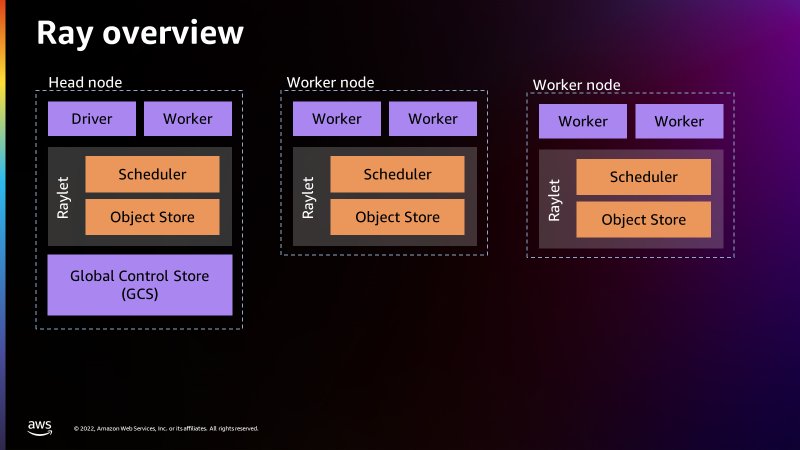
When working a Ray job, AWS Glue provisions the Ray cluster for you and runs these distributed Python jobs on a serverless auto-scaling infrastructure. The cluster in AWS Glue for Ray will consists of precisely one head node and a number of employee nodes.
The top node is similar to the opposite employee nodes with the exception that it runs singleton processes for cluster administration and the Ray driver course of. The driving force is a particular employee course of within the head node that runs the top-level utility in Python that begins the Ray job. The employee node has processes which might be chargeable for submitting and working duties.
The next determine offers a easy introduction to the Ray structure. The structure illustrates how Ray is ready to schedule jobs via processes referred to as Raylets. The Raylet manages the shared assets on every node and is shared between the concurrently working jobs. For extra info on how Ray works, see Ray.io.
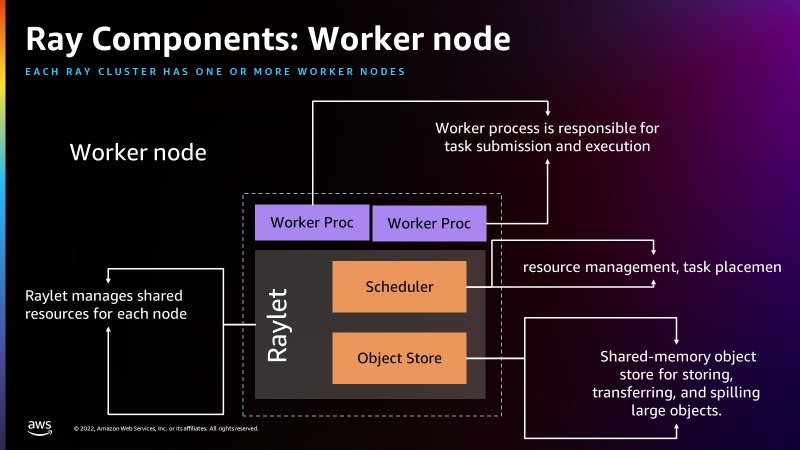
The next determine reveals the elements of the employee node and the shared-memory object retailer:
There’s a International Management Retailer within the head node that may deal with every separate machine as nodes, just like how Apache Spark treats employees as nodes. The next determine reveals the elements of the pinnacle node and the International Management Retailer managing the cluster-level metadata.

AWS Glue for Ray comes included with Ray Core, Ray Dataset, Modin (distributed pandas) and the AWS SDK for pandas (on Modin) for seamless distributed integration into different AWS providers. Ray Core is the inspiration of Ray and the essential framework for distributing Python capabilities and courses. Ray Dataset is a distributed knowledge framework based mostly on Apache Arrow and is most intently analogous to a dataframe in Apache Spark. Modin is a library designed to distribute pandas purposes throughout a Ray cluster with none modification and is appropriate with knowledge in Ray Datasets. The included AWS SDK for pandas (previously AWS Information Wrangler) is an abstraction layer on prime of Modin to permit for the creation of pandas dataframes from (and writing to) many AWS sources resembling Amazon Easy Storage Service (Amazon S3), Amazon Redshift, Amazon DynamoDB, Amazon OpenSearch Service, and others.
You may also set up your individual ARM appropriate Python libraries by way of pip, both via Ray’s environmental configuration in @ray.distant or by way of --additional-python-modules.
To be taught extra about Ray, please go to the GitHub repo.
Why use AWS Glue for Ray?
Many people begin our knowledge journey on AWS with Python, trying to put together knowledge for ML and knowledge science, and transfer knowledge at scale with AWS APIs and Boto3. Ray permits you to carry these acquainted abilities, paradigms, frameworks and libraries to AWS Glue and make them scale to deal with huge datasets with minimal code modifications. You need to use the identical knowledge processing instruments you at present have (resembling Python libraries for knowledge cleaning, computation, and ML) on datasets of all sizes. AWS Glue for Ray permits the distributed run of your Python scripts over multi-node clusters.
AWS Glue for Ray is designed for the next:
- Job parallel purposes (for instance, whenever you wish to apply a number of transforms in parallel)
- Dashing up your Python workload in addition to utilizing Python native libraries.
- Operating the identical workload throughout tons of of knowledge sources.
- ML ingestion and parallel batch inference on knowledge
Answer overview
For this submit, you’ll use the Parquet Amazon Buyer Opinions Dataset saved within the public S3 bucket. The target is to carry out transformations utilizing the Ray dataset after which write it again to Amazon S3 within the Parquet file format.
Configure Amazon S3
Step one is to create an Amazon S3 bucket to retailer the remodeled Parquet dataset as the tip end result.
- On the Amazon S3 console, select Buckets within the navigation pane.
- Select Create bucket.
- For Bucket title, enter a reputation to your Amazon S3 bucket.

- Select Create.
Arrange a Jupyter pocket book with an AWS Glue interactive session
For our improvement atmosphere, we use a Jupyter pocket book to run the code.
You’re required to put in the AWS Glue interactive periods domestically or run interactive periods with an AWS Glue Studio pocket book. Utilizing AWS Glue Interactive periods will show you how to comply with and run the collection of demonstration steps.
Confer with Getting began with AWS Glue interactive periods for directions to spin up a pocket book on an AWS Glue interactive session.
Run your code utilizing Ray in a Jupyter pocket book
This part walks you thru a number of pocket book paragraphs on use AWS Glue for Ray. On this train, we have a look at the shopper evaluations from the Amazon Buyer Overview Parquet dataset, carry out some Ray transformations, and write the outcomes to Amazon S3 in a Parquet format.
- On Jupyter console, below New, select Glue Python.
- Signify you wish to use Ray because the engine by utilizing the
%glue_raymagic. - Import the Ray library together with extra Python libraries:
- Initialize a Ray Cluster with AWS Glue.
- Subsequent, we learn a single partition from the dataset, which is Parquet file format:

- Parquet information retailer the variety of rows per file within the metadata, so we will get the whole variety of information in ds with out performing a full knowledge learn:

- Subsequent , we will verify the schema of this dataset. We don’t need to learn the precise knowledge to get the schema; we will learn it from the metadata:

- We are able to verify the whole dimension in bytes for the complete Ray dataset:

- We are able to see a pattern file from the Ray dataset:


Making use of dataset transformations with Ray
There are primarily two kinds of transformations that may be utilized to Ray datasets:
- One-to-One transformations – Every enter block will contributes to just one output block, resembling
add_column(),map_batches()anddrop_column(), and so forth. - All-to-All transformations – Enter blocks can contribute to a number of output blocks resembling
type()andgroupby(), and so forth.
Within the subsequent collection of steps we are going to apply a few of these transformations on our resultant Ray datasets from the earlier part.
- We are able to add a brand new column and verify the schema to confirm the newly added column, adopted by retrieving a pattern file. This transformation is barely obtainable for the datasets that may be transformed to pandas format.


- Let’s drop just a few columns we don’t want utilizing a
drop_columnstransformation after which verify the schema to confirm if these columns are dropped from the Ray dataset:

Ray datasets have built-in transformations resembling sorting the dataset by the desired key column or key operate. - Subsequent, we apply the kind transformation utilizing one of many columns current within the dataset (
total_votes):

- Subsequent, we are going to create a Python UDF operate that permits you to write personalized enterprise logic in transformations. In our UDF we have now written a logic to search out out the merchandise which might be rated low (i.e. complete votes lower than 100).We create a UDF as a operate on pandas DataFrame batches. For the supported enter batch codecs, see the UDF Enter Batch Format. We additionally exhibit utilizing
map_batches()which applies the given operate to the batches of information of this dataset.Map_batches()makes use of the default compute technique (duties), which helps distribute the information processing to a number of Ray employees, that are used to run duties. For extra info on amap_batches()transformation, please see the following documentation.

- If in case you have complicated transformations that require extra assets for knowledge processing, we suggest using Ray actors utilizing extra configurations with relevant transformations. We now have demonstrated with
map_batches()under: - Subsequent, earlier than writing the ultimate resultant Ray dataset we are going to apply
map_batches()transformations to filter out the shopper evaluations knowledge the place the whole votes for a given product is bigger than 0 and the evaluations belongs to the “US” market solely. Utilizingmap_batches()for the filter operation is best by way of efficiency compared tofilter()transformation.
- Lastly, we write the resultant knowledge to the S3 bucket you created in a Parquet file format. You need to use totally different dataset APIs obtainable, resembling
write_csv()orwrite_json()for various file codecs. Moreover, you possibly can convert the resultant dataset to a different DataFrame sort resembling Mars, Modin or pandas.
Clear up
To keep away from incurring future prices, delete the Amazon S3 bucket and Jupyter pocket book.
- On the Amazon S3 console, select Buckets.
- Select the bucket you created.
- Select Empty and enter your bucket title.
- Select Verify.
- Select Delete and enter your bucket title.
- Select Delete bucket.
- On the AWS Glue console, select Interactive Classes
- Select the interactive session you created.
- Select Delete to take away the interactive session.
Conclusion
On this submit, we demonstrated how you need to use AWS Glue for Ray to run your Python code in a distributed atmosphere. Now you can run your knowledge and ML purposes in a multi-node atmosphere.
Confer with the Ray documentation for added info and use instances.
Concerning the authors
 Zach Mitchell is a Sr. Huge Information Architect. He works inside the product staff to boost understanding between product engineers and their prospects whereas guiding prospects via their journey to develop knowledge lakes and different knowledge options on AWS analytics providers.
Zach Mitchell is a Sr. Huge Information Architect. He works inside the product staff to boost understanding between product engineers and their prospects whereas guiding prospects via their journey to develop knowledge lakes and different knowledge options on AWS analytics providers.
 Ishan Gaur works as Sr. Huge Information Cloud Engineer ( ETL ) specialised in AWS Glue. He’s enthusiastic about serving to prospects construct out scalable distributed ETL workloads and implement scalable knowledge processing and analytics pipelines on AWS. When not at work, Ishan likes to cook dinner, journey together with his household, or take heed to music.
Ishan Gaur works as Sr. Huge Information Cloud Engineer ( ETL ) specialised in AWS Glue. He’s enthusiastic about serving to prospects construct out scalable distributed ETL workloads and implement scalable knowledge processing and analytics pipelines on AWS. When not at work, Ishan likes to cook dinner, journey together with his household, or take heed to music.
 Derek Liu is a Options Architect on the Enterprise staff based mostly out of Vancouver, BC. He’s a part of the AWS Analytics area group and enjoys serving to prospects clear up large knowledge challenges via AWS analytic providers.
Derek Liu is a Options Architect on the Enterprise staff based mostly out of Vancouver, BC. He’s a part of the AWS Analytics area group and enjoys serving to prospects clear up large knowledge challenges via AWS analytic providers.
 Kinshuk Pahare is a Principal Product Supervisor on AWS Glue.
Kinshuk Pahare is a Principal Product Supervisor on AWS Glue.





