
Enterprise prospects are modernizing their information warehouses and information lakes to supply real-time insights, as a result of having the suitable insights on the proper time is essential for good enterprise outcomes. To allow near-real-time decision-making, information pipelines have to course of real-time or near-real-time information. This information is sourced from IoT gadgets, change information seize (CDC) companies like AWS Information Migration Service (AWS DMS), and streaming companies reminiscent of Amazon Kinesis, Apache Kafka, and others. These information pipelines have to be sturdy, in a position to scale, and in a position to course of giant information volumes in near-real time. AWS Glue streaming extract, remodel, and cargo (ETL) jobs course of information from information streams, together with Kinesis and Apache Kafka, apply advanced transformations in-flight, and cargo it right into a goal information shops for analytics and machine studying (ML).
Lots of of consumers are utilizing AWS Glue streaming ETL for his or her near-real-time information processing necessities. These prospects required an interactive functionality to course of streaming jobs. Beforehand, when growing and operating a streaming job, you needed to look ahead to the outcomes to be out there within the job logs or endured right into a goal information warehouse or information lake to have the ability to view the outcomes. With this method, debugging and adjusting code is troublesome, leading to an extended improvement timeline.
Right this moment, we’re launching a brand new AWS Glue streaming ETL function to interactively develop streaming ETL jobs in AWS Glue Studio notebooks and interactive periods.
On this put up, we offer a use case and step-by-step directions to develop and debug your AWS Glue streaming ETL job utilizing a pocket book.
Answer overview
To show the streaming interactive periods functionality, we develop, check, and deploy an AWS Glue streaming ETL job to course of Apache Webserver logs. The next high-level diagram represents the stream of occasions in our job.
Apache Webserver logs are streamed to Amazon Kinesis Information Streams. An AWS Glue streaming ETL job consumes the information in near-real time and runs an aggregation that computes what number of instances a webpage has been unavailable (standing code 500 and above) because of an inside error. The mixture data is then printed to a downstream Amazon DynamoDB desk. As a part of this put up, we develop this job utilizing AWS Glue Studio notebooks.
You may both work with the directions offered within the pocket book, which you obtain when instructed later on this put up, or comply with together with this put up to writer your first streaming interactive session job.
Conditions
To get began, click on the Launch Stack button beneath, to run an AWS CloudFormation template in your AWS surroundings.
![]()
The template provisions a Kinesis information stream, DynamoDB desk, AWS Glue job to generate simulated log information, and the required AWS Id and Entry Administration (IAM) function and polices. After you deploy your assets, you may overview the Assets tab on the AWS CloudFormation console for detailed data.
Arrange the AWS Glue streaming interactive session job
To arrange your AWS Glue streaming job, full the next steps:
- Obtain the pocket book file and reserve it to an area listing in your laptop.
- On the AWS Glue console, select Jobs within the navigation pane.
- Select Create job.
- Choose Jupyter Pocket book.
- Below Choices, choose Add and edit an current pocket book.
- Select Select file and browse to the pocket book file you downloaded.
- Select Create.
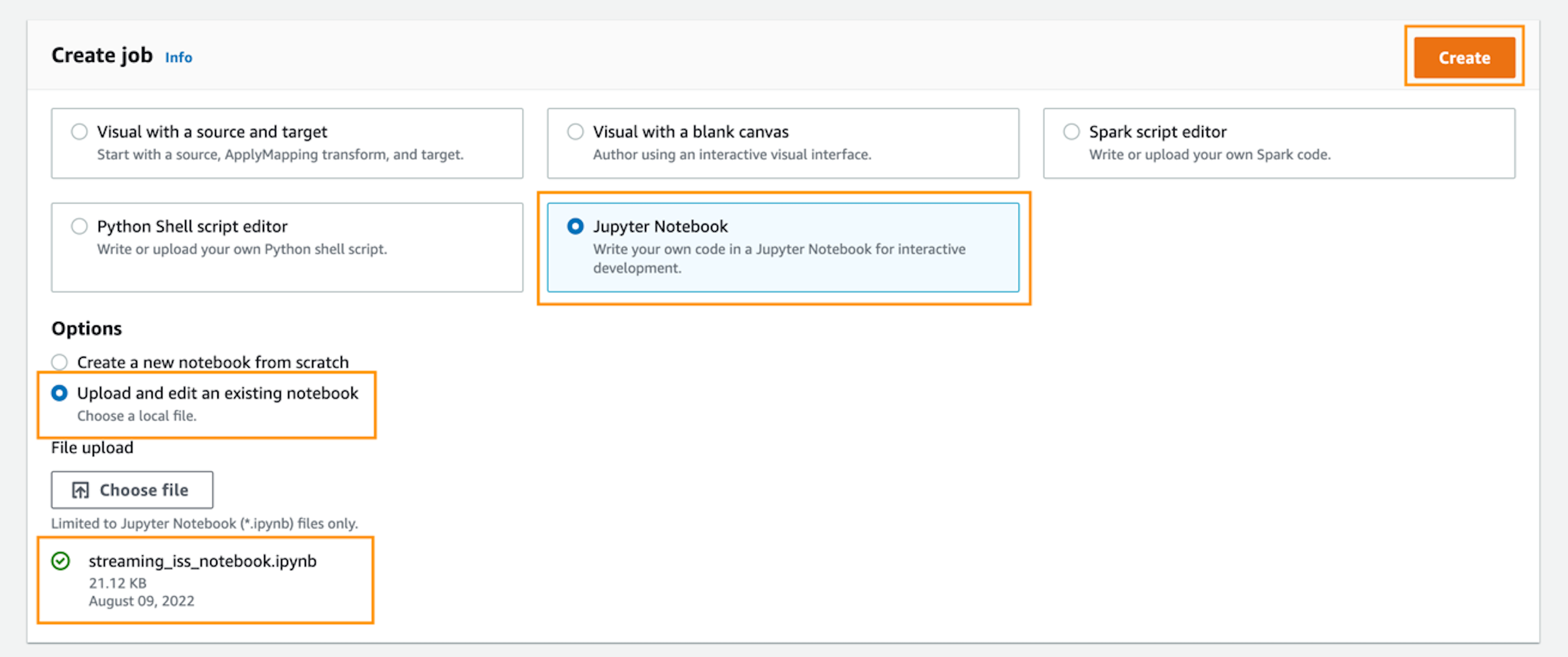
- For Job title¸ enter a reputation for the job.
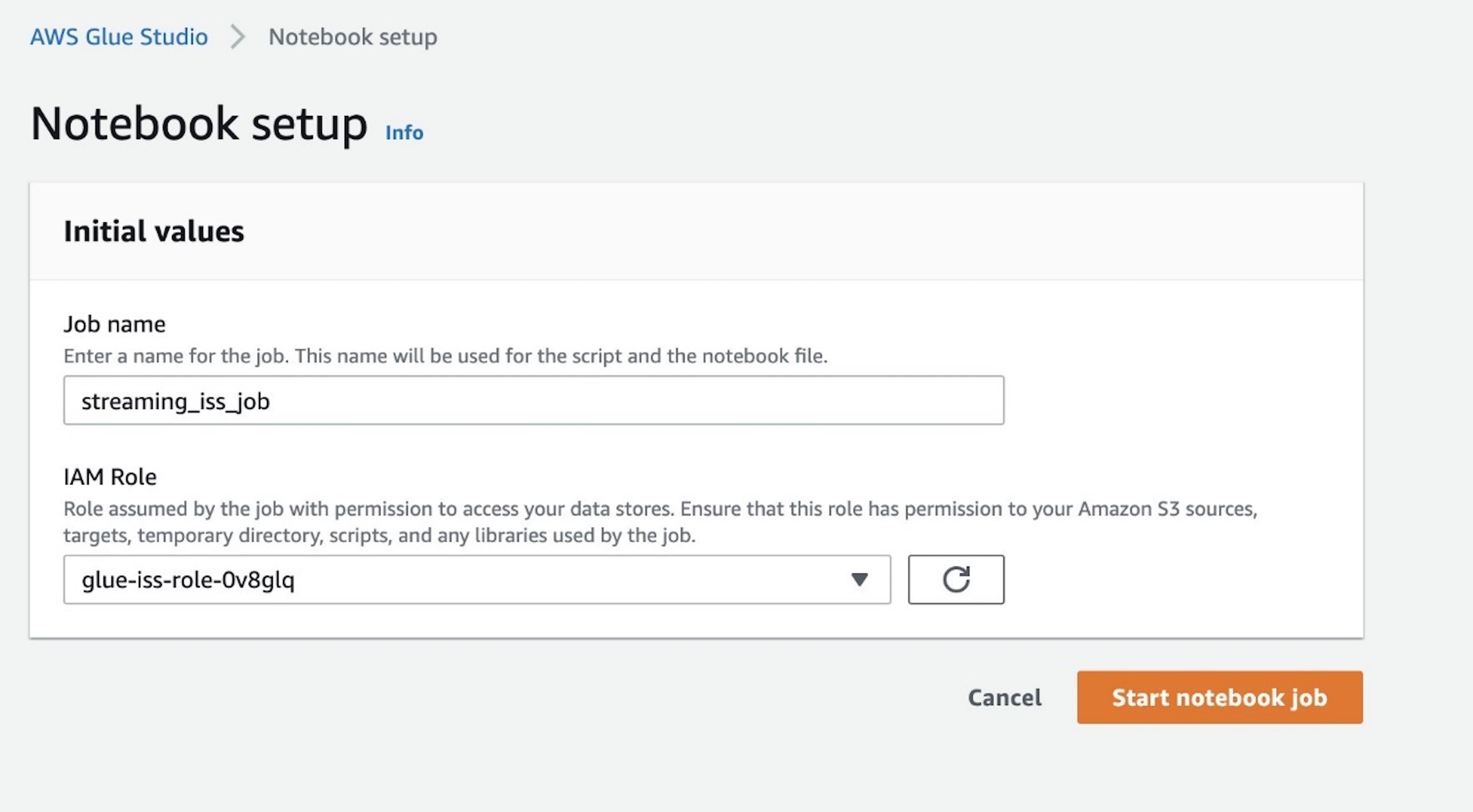
- For IAM Position, use the function
glue-iss-role-0v8glq, which is provisioned as a part of the CloudFormation template. - Select Begin pocket book job.
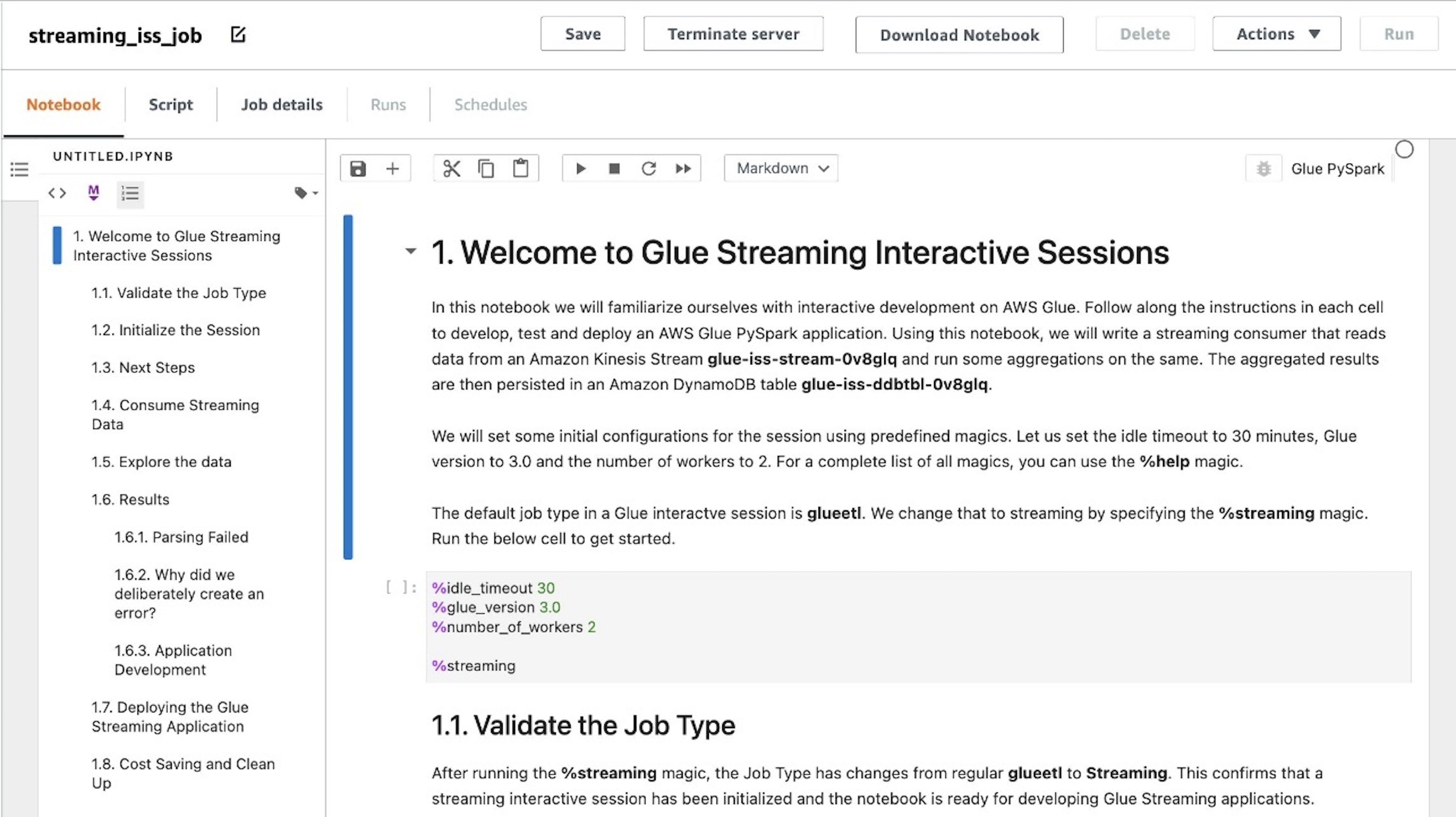
You may see that the pocket book is loaded into the UI. There are markdown cells with directions in addition to code blocks that you would be able to run sequentially. You may both run the directions on the pocket book or comply with together with this put up to proceed with the job improvement.
Run pocket book cells
Let’s run the code block that has the magics. The pocket book has notes on what every magic does.
- Run the primary cell.
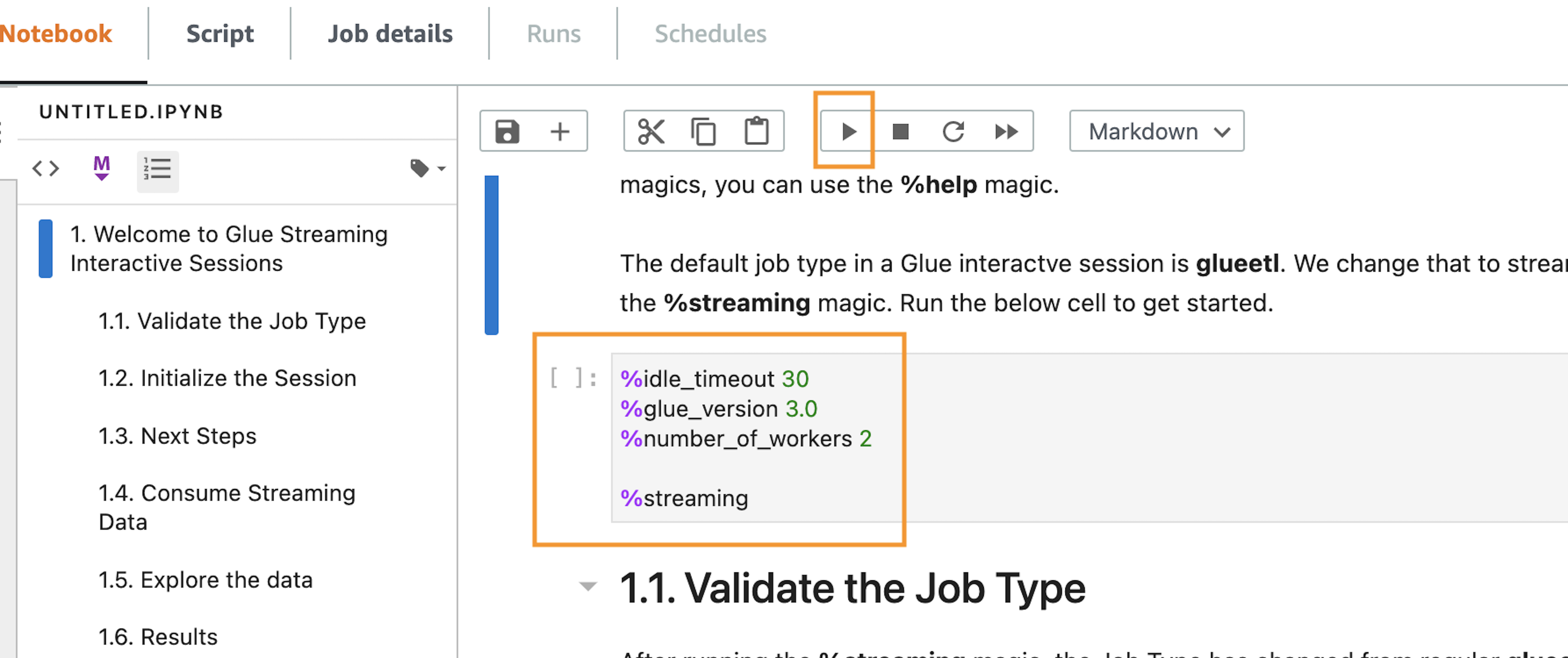
After operating the cell, you may see within the output part that the defaults have been reconfigured.
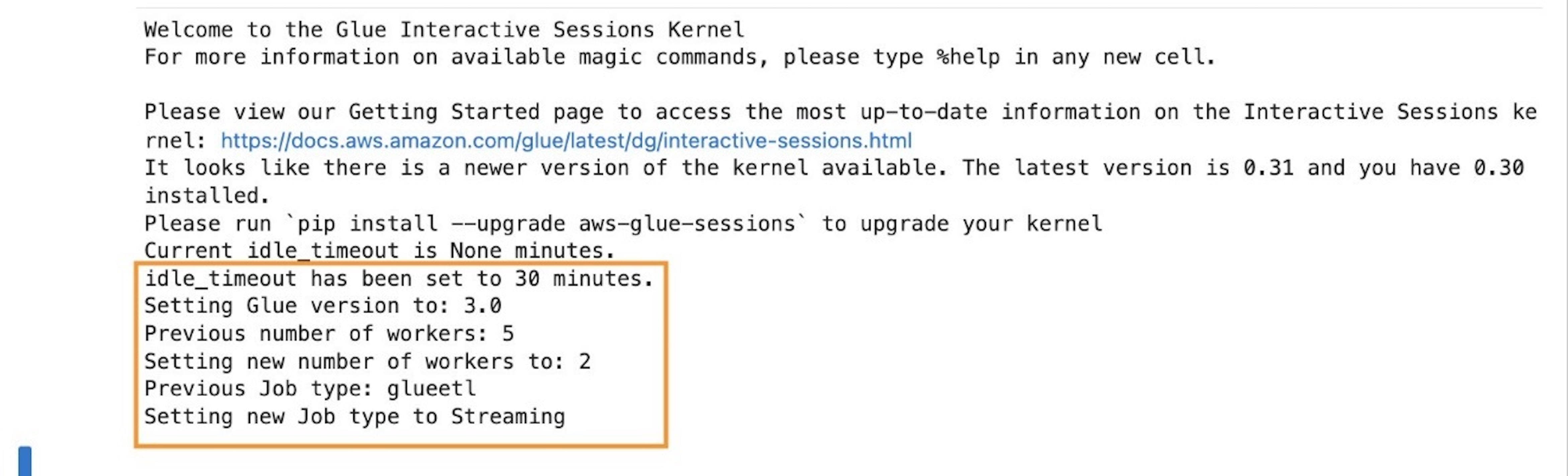
Within the context of streaming interactive periods, an necessary configuration is job sort, which is ready to streaming. Moreover, to attenuate prices, the variety of employees is ready to 2 (default 5), which is adequate for our use case that offers with a low-volume simulated dataset.
Our subsequent step is to initialize an AWS Glue streaming session.
- Run the following code cell.
After we run this cell, we will see {that a} session has been initialized and a session ID is created.
A Kinesis information stream and AWS Glue information generator job that feeds into this stream have already been provisioned and triggered by the CloudFormation template. With the following cell, we devour this information as an Apache Spark DataFrame.
- Run the following cell.
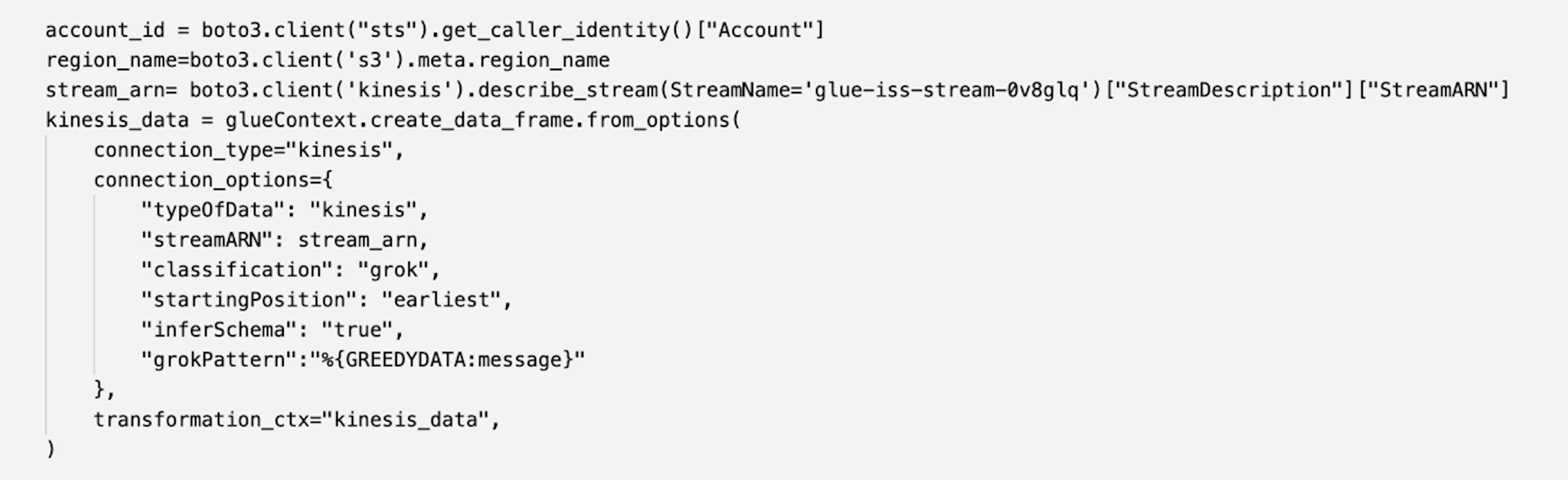
As a result of there are not any print statements, the cells don’t present any output. You may proceed to run the next cells.
Discover the information stream
To assist improve the interactive expertise in AWS Glue interactive periods, GlueContext supplies the strategy getSampleStreamingDynamicFrame. It supplies a snapshot of the stream in a static DynamicFrame. It takes three arguments:
- The Spark streaming DataFrame
- An choices map
- A
writeStreamFunctionto use a operate to each sampled document
Out there choices are as follows:
- windowSize – Also referred to as the micro-batch length, this parameter determines how lengthy a streaming question will wait after the earlier batch was triggered.
- pollingTimeInMs – That is the entire size of time the strategy will run. It begins not less than one micro-batch to acquire pattern data from the enter stream. The time unit is milliseconds, and the worth ought to be better than the
windowSize. - recordPollingLimit – That is defaulted to 100, and helps you set an higher sure on the variety of data that’s retrieved from the stream.
Run the following code cell and discover the output.
We see that the pattern consists of 100 data (the default document restrict), and we have now efficiently displayed the primary 10 data from the pattern.
Work with the information
Now that we all know what our information appears like, we will write the logic to scrub and format it for our analytics.
Run the code cell containing the reformat operate.
Word that Python UDFs aren’t the really useful technique to deal with information transformations in a Spark utility. We use reformat() to exemplify troubleshooting. When working with a real-world manufacturing utility, we suggest utilizing native APIs wherever attainable.
We see that the code cell did not run. The failure was on objective. We intentionally created a division by zero exception in our parser.
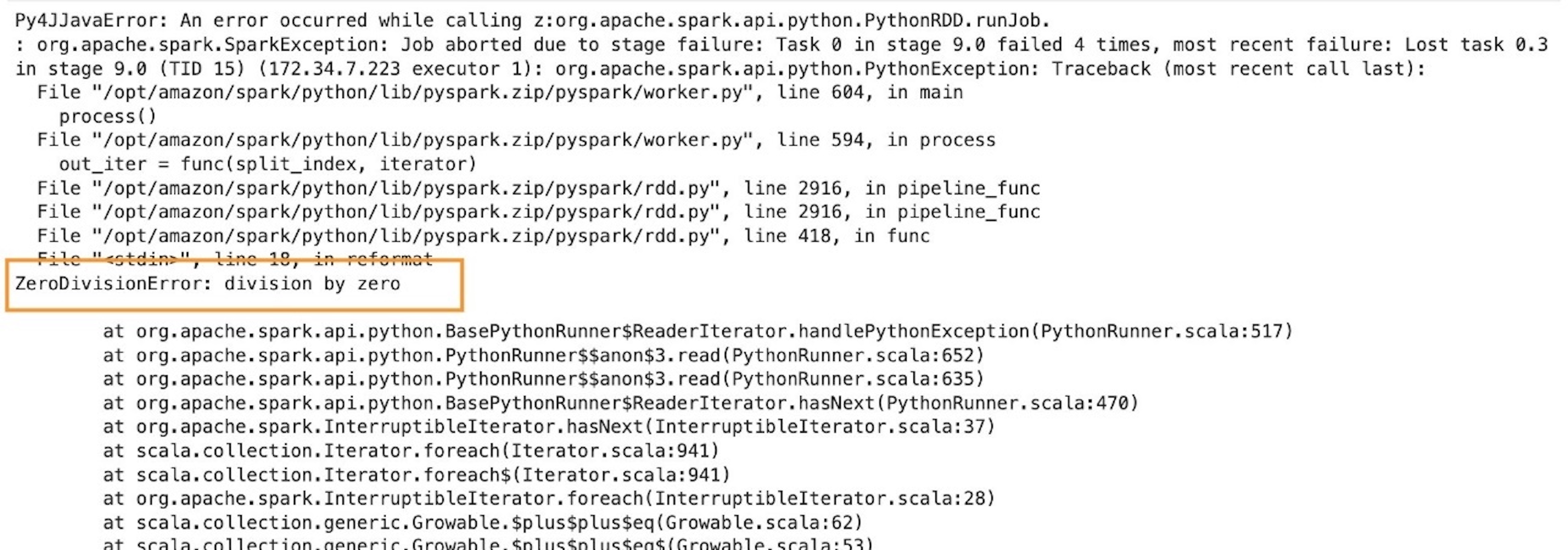
Failure and restoration
In case of a daily AWS Glue job, for any error, the entire utility exits, and it’s important to make code modifications and resubmit the appliance. Nonetheless, in case of interactive periods, the coding context and definitions are totally preserved and the session remains to be operational. There isn’t a have to bootstrap a brand new cluster and rerun all of the previous transformation. This lets you give attention to rapidly iterating your batch operate implementation to acquire the specified consequence. You may repair the defects and run them in a matter of seconds.
To check this out, return to the code and remark or delete the inaccurate line error_line=1/0 and rerun the cell.
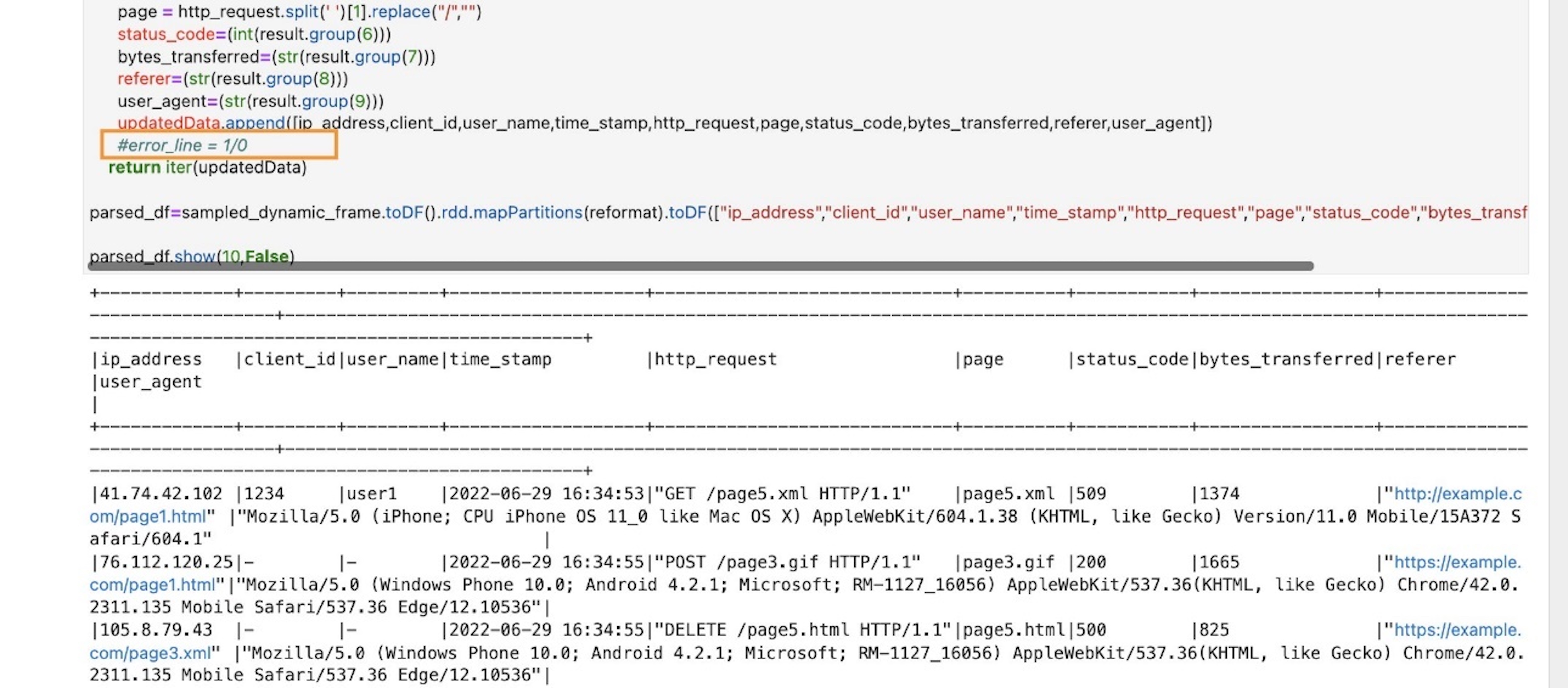
Implement enterprise logic
Now that we have now efficiently examined our parsing logic on the pattern stream, let’s implement the precise enterprise logic. The logics are carried out within the processBatch methodology inside the subsequent code cell. On this methodology, we do the next:
- Go the streaming DataFrame in micro-batches
- Parse the enter stream
- Filter messages with standing code >=500
- Over a 1-minute interval, get the rely of failures per webpage
- Persist the previous metric to a DynamoDB desk (
glue-iss-ddbtbl-0v8glq)
- Run the following code cell to set off the stream processing.

- Wait a couple of minutes for the cell to finish.
- On the DynamoDB console, navigate to the Gadgets web page and choose the
glue-iss-ddbtbl-0v8glqdesk.
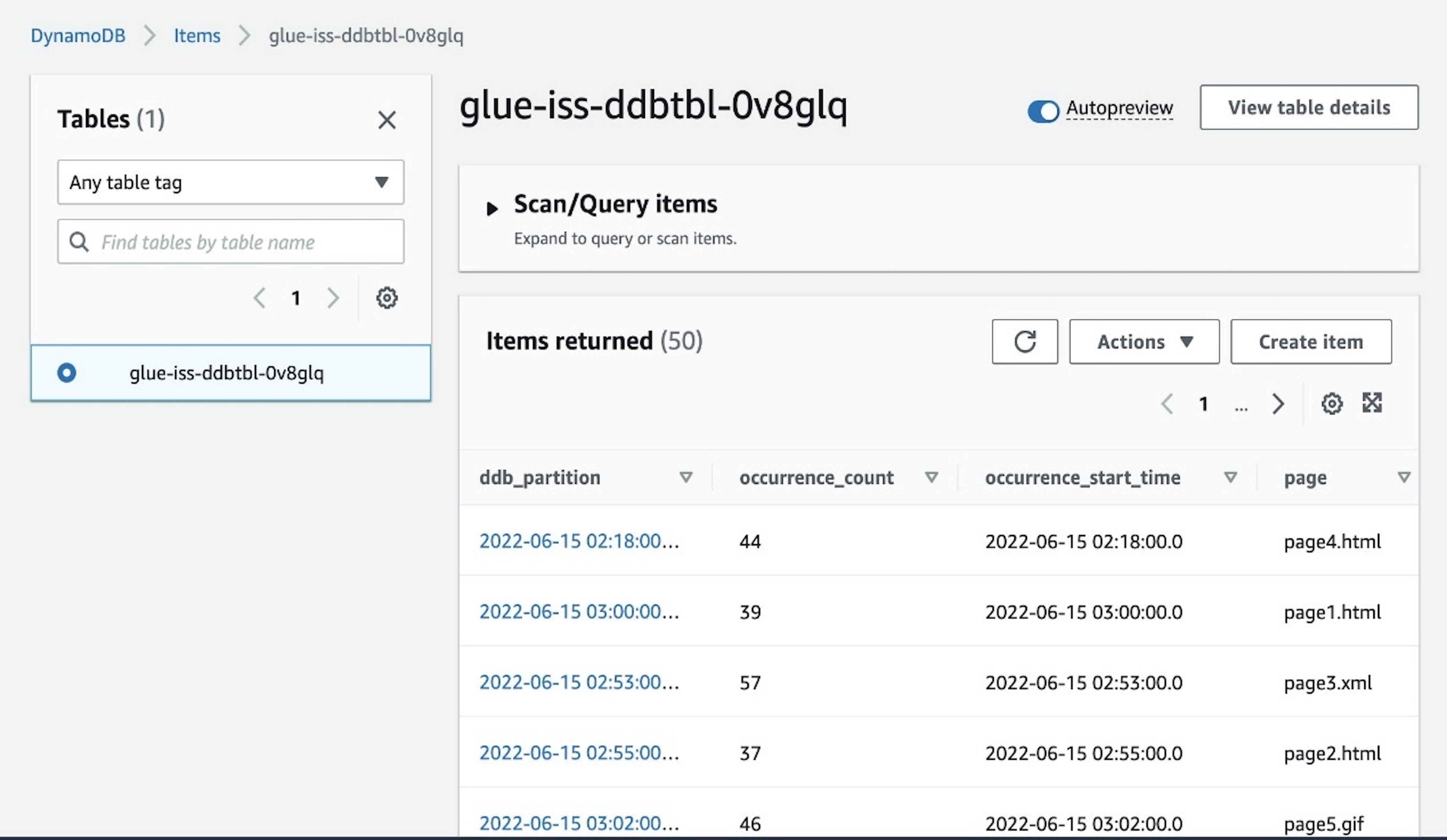
The web page shows the aggregated outcomes which have been written by our interactive session job.
Deploy the streaming job
Thus far, we have now been growing and testing our utility utilizing the streaming interactive periods. Now that we’re assured of the job, let’s convert this into an AWS Glue job. We now have seen that almost all of code cells are doing exploratory evaluation and sampling, and aren’t required to be part of the principle job.
A commented code cell that represents the entire utility is offered to you. You may uncomment the cell and delete all different cells. An alternative choice could be to not use the commented cell, however delete simply the 2 cells from the pocket book that do the sampling or debugging and print statements.
To delete a cell, select the cell after which select the delete icon.
Now that you’ve got the ultimate utility code prepared, save and deploy the AWS Glue job by selecting Save.

A banner message seems when the job is up to date.

Discover the AWS Glue job
After you save the pocket book, you need to have the ability to entry the job like every common AWS Glue job on the Jobs web page of the AWS Glue console.
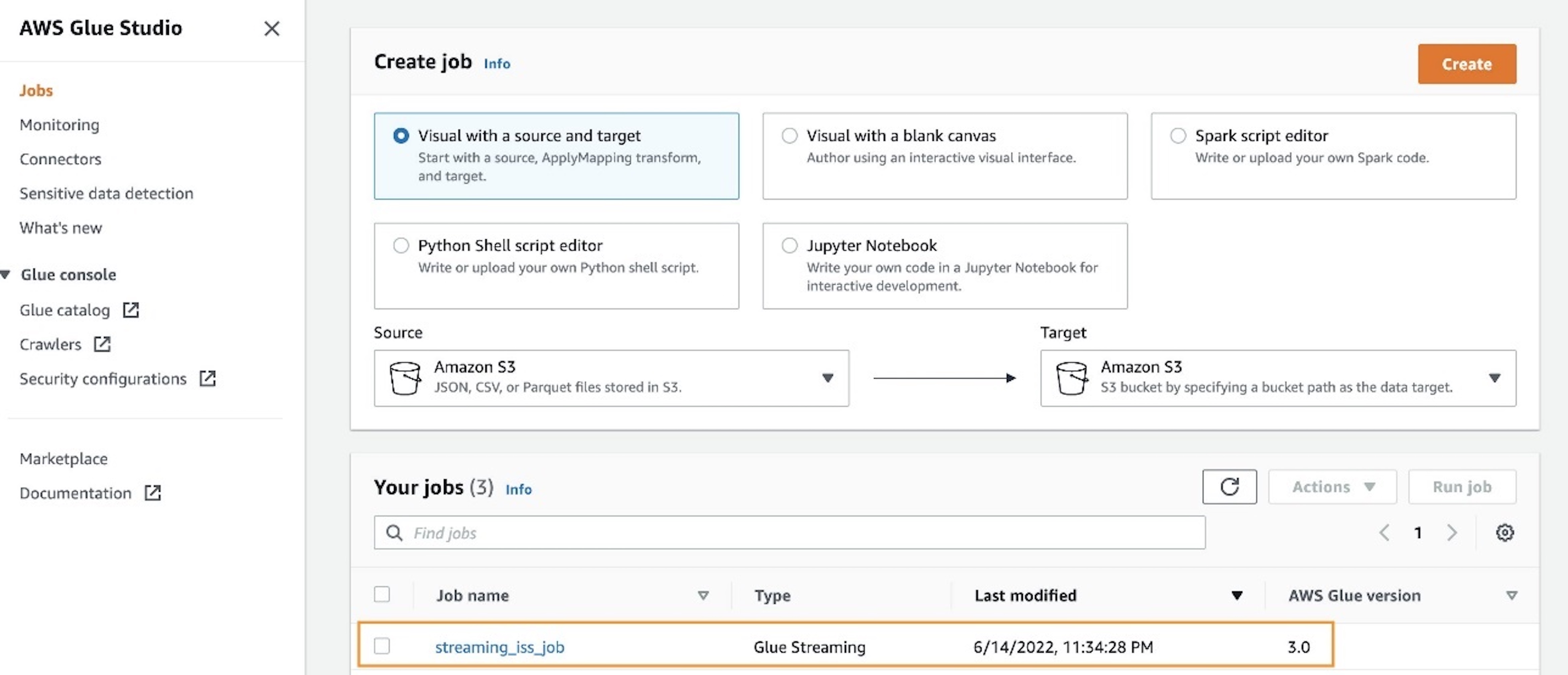
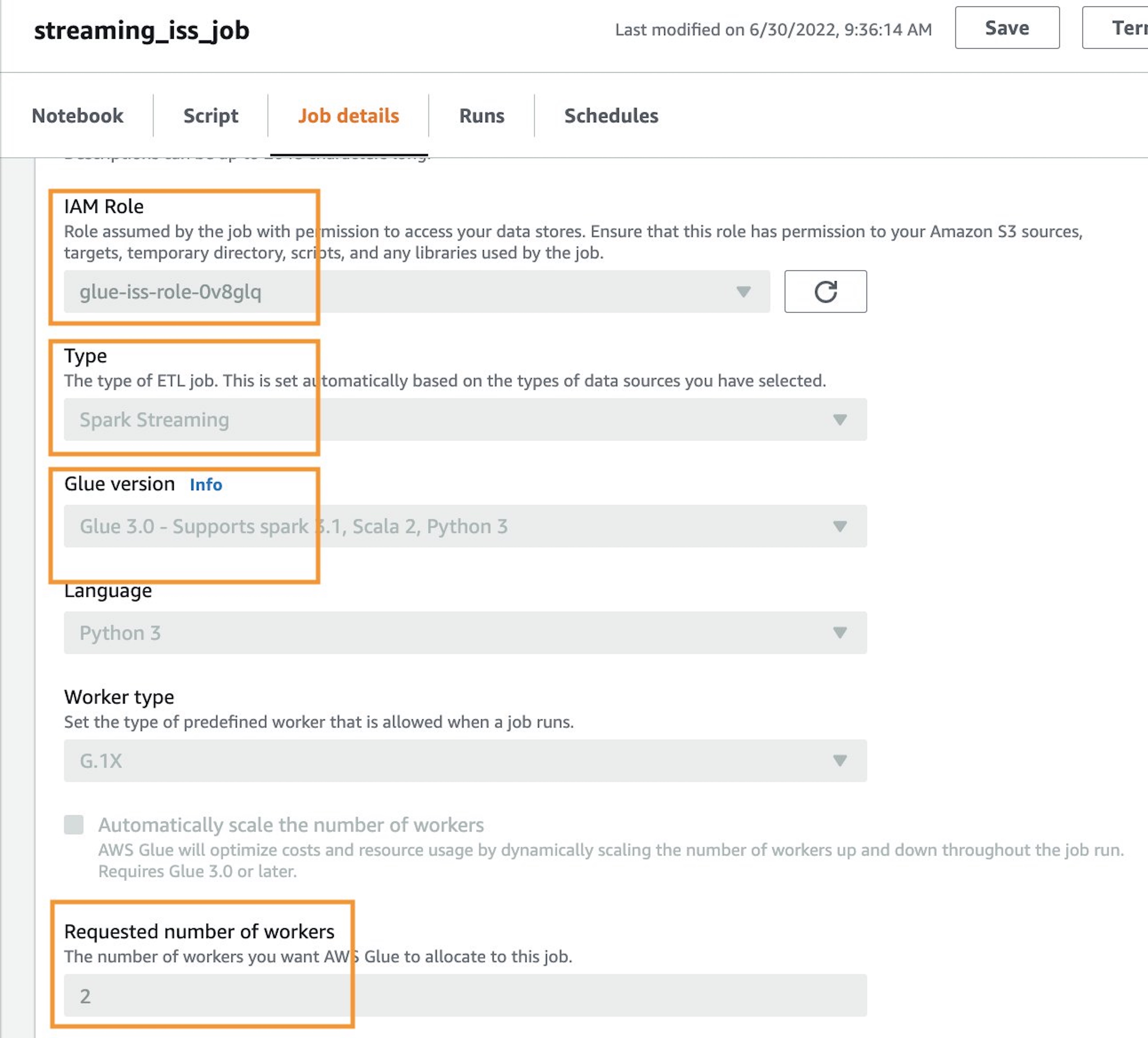
Moreover, you may have a look at the Job particulars tab to verify the preliminary configurations, reminiscent of variety of employees, have taken impact after deploying the job.
Run the AWS Glue job
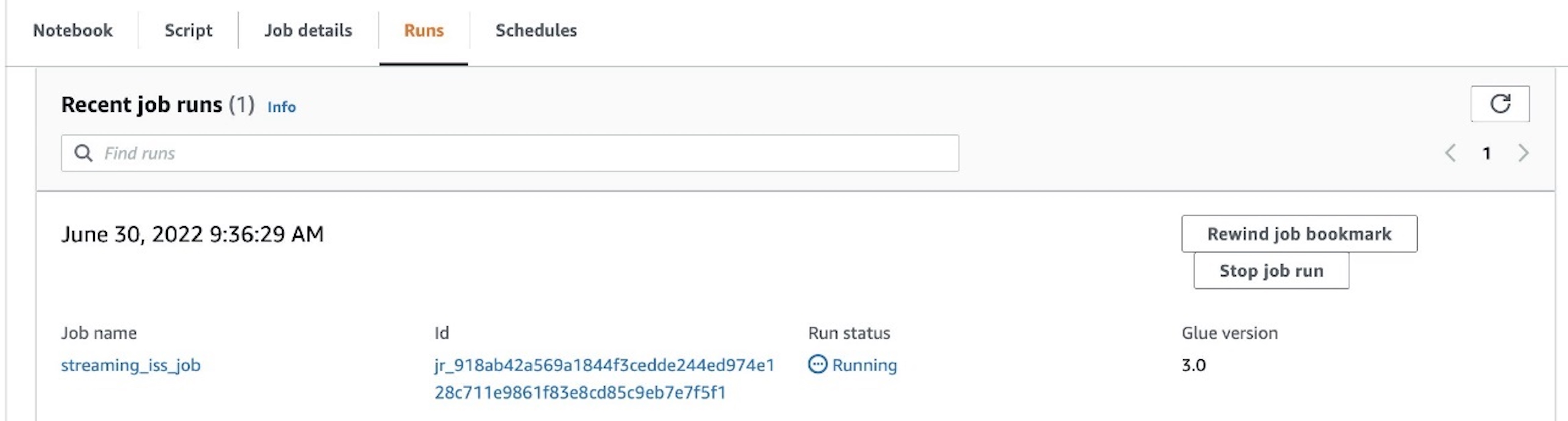
If wanted, you may select Run to run the job as an AWS Glue streaming job.
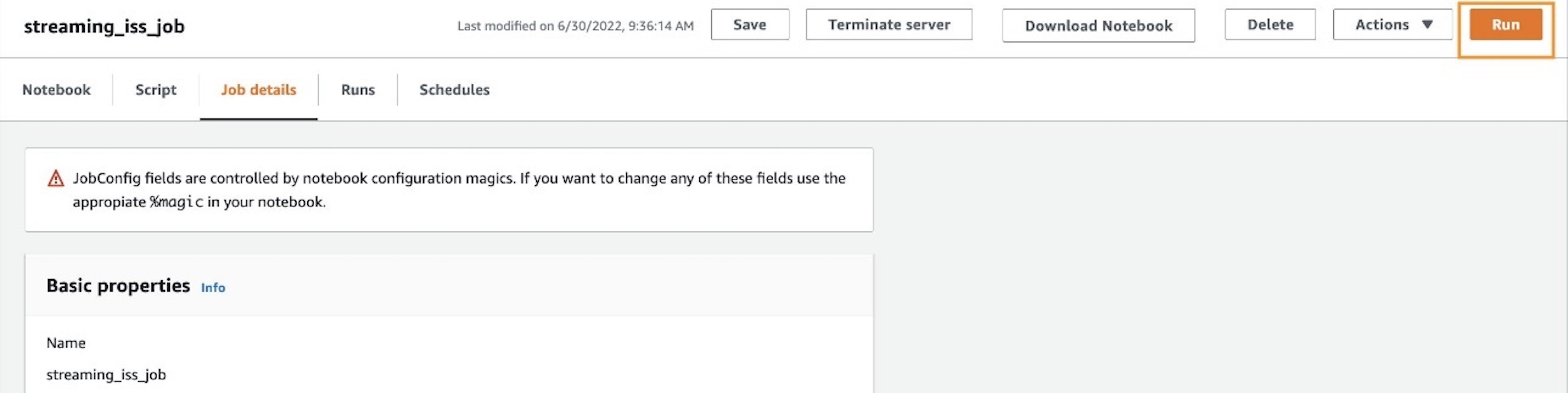
To trace progress, you may entry the run particulars on the Runs tab.
Clear up
To keep away from incurring further prices to your account, cease the streaming job that you just began as a part of the directions. Additionally, on the AWS CloudFormation console, choose the stack that you just provisioned and delete it.
Conclusion
On this put up, we demonstrated easy methods to do the next:
- Writer a job utilizing notebooks
- Preview incoming information streams
- Code and repair points with out having to publish AWS Glue jobs
- Overview the end-to-end working code, take away any debugging, and print statements or cells from the pocket book
- Publish the code as an AWS Glue job
We did all of this through a pocket book interface.
With these enhancements within the total improvement timelines of AWS Glue jobs, it’s simpler to writer jobs utilizing the streaming interactive periods. We encourage you to make use of the prescribed use case, CloudFormation stack, and pocket book to jumpstart your particular person use circumstances to undertake AWS Glue streaming workloads.
The objective of this put up was to present you hands-on expertise working with AWS Glue streaming and interactive periods. When onboarding a productionized workload onto your AWS surroundings, primarily based on the information sensitivity and safety necessities, make sure you implement and implement tighter safety controls.
Concerning the authors
 Arun A Ok is a Massive Information Options Architect with AWS. He works with prospects to supply architectural steering for operating analytics options on the cloud. In his free time, Arun likes to take pleasure in high quality time together with his household.
Arun A Ok is a Massive Information Options Architect with AWS. He works with prospects to supply architectural steering for operating analytics options on the cloud. In his free time, Arun likes to take pleasure in high quality time together with his household.
 Linan Zheng is a Software program Growth Engineer at AWS Glue Streaming Workforce, serving to constructing the serverless information platform. His works contain giant scale optimization engine for transactional information codecs and streaming interactive periods.
Linan Zheng is a Software program Growth Engineer at AWS Glue Streaming Workforce, serving to constructing the serverless information platform. His works contain giant scale optimization engine for transactional information codecs and streaming interactive periods.
 Roman Gavrilov is an Engineering Supervisor at AWS Glue. He has over a decade of expertise constructing scalable Massive Information and Occasion-Pushed options. His workforce works on Glue Streaming ETL to permit close to actual time information preparation and enrichment for machine studying and analytics.
Roman Gavrilov is an Engineering Supervisor at AWS Glue. He has over a decade of expertise constructing scalable Massive Information and Occasion-Pushed options. His workforce works on Glue Streaming ETL to permit close to actual time information preparation and enrichment for machine studying and analytics.
 Shiv Narayanan is a Senior Technical Product Supervisor on the AWS Glue workforce. He works with AWS prospects throughout the globe to strategize, construct, develop, and deploy trendy information platforms.
Shiv Narayanan is a Senior Technical Product Supervisor on the AWS Glue workforce. He works with AWS prospects throughout the globe to strategize, construct, develop, and deploy trendy information platforms.





