
This can be a visitor publish by Nan Zhu, Tech Lead Supervisor, SafeGraph, and Dave Thibault, Sr. Options Architect – AWS
SafeGraph is a geospatial knowledge firm that curates over 41 million world factors of curiosity (POIs) with detailed attributes, comparable to model affiliation, superior class tagging, and open hours, in addition to how individuals work together with these locations. We use Apache Spark as our most important knowledge processing engine and have over 1,000 Spark functions operating over huge quantities of knowledge on daily basis. These Spark functions implement our enterprise logic starting from knowledge transformation, machine studying (ML) mannequin inference, to operational duties.
SafeGraph discovered itself with a less-than-optimal Spark atmosphere with their incumbent Spark vendor. Their prices have been climbing. Their jobs would endure frequent retries from Spot Occasion termination. Builders spent an excessive amount of time troubleshooting and altering job configurations and never sufficient time delivery enterprise worth code. SafeGraph wanted to regulate prices, enhance developer iteration pace, and enhance job reliability. In the end, SafeGraph selected Amazon EMR on Amazon EKS to fulfill their wants and realized 50% financial savings relative to their earlier Spark managed service vendor.
If constructing Spark functions for our product is like slicing a tree, having a pointy noticed turns into essential. The Spark platform is the noticed. The next determine highlights the engineering workflow when working with Spark, and the Spark platform ought to assist and optimize every motion within the workflow. The engineers often begin with writing and constructing the Spark utility code, then submit the applying to the computing infrastructure, and at last shut the loop by debugging the Spark functions. Moreover, platform and infrastructure groups want to repeatedly function and optimize the three steps within the engineering workflow.
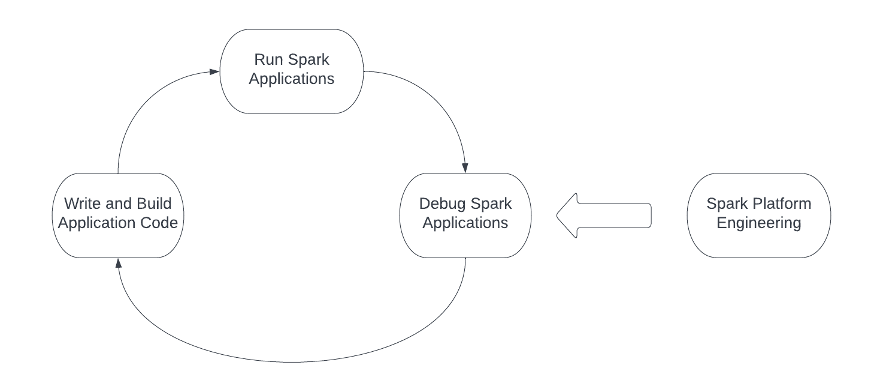
There are numerous challenges concerned in every motion when constructing a Spark platform:
- Dependable dependency administration – An advanced Spark utility often brings many dependencies. To run a Spark utility, we have to determine all dependencies, resolve any conflicts, pack dependent libraries reliably, and ship them to the Spark cluster. Dependency administration is among the largest challenges for engineers, particularly after they work with PySpark functions.
- Dependable computing infrastructure – The reliability of the computing infrastructure internet hosting Spark functions is the muse of the entire Spark platform. Unstable useful resource provisioning is not going to solely trigger unfavorable impression over engineering effectivity, however it is going to additionally improve infrastructure prices as a consequence of reruns of the Spark functions.
- Handy debugging instruments for Spark functions – The debugging tooling performs a key function for engineers to iterate quick on Spark functions. Performant entry to the Spark Historical past Server (SHS) is a should for developer iteration pace. Conversely, poor SHS efficiency slows builders and will increase the price of items bought for software program corporations.
- Manageable Spark infrastructure – A profitable Spark platform engineering includes a number of features, comparable to Spark distribution model administration, computing useful resource SKU administration and optimization, and extra. It largely is determined by whether or not the Spark service distributors present the best basis for platform groups to make use of. The mistaken abstraction over distribution model and computing assets, for instance, might considerably scale back the ROI of platform engineering.
At SafeGraph, we skilled the entire aforementioned challenges. To resolve them, we explored {the marketplace} and located that constructing a brand new Spark platform on high of EMR on EKS was the answer to our roadblocks. On this publish, we share our journey of constructing our newest Spark platform and the way EMR on EKS serves as a sturdy and environment friendly basis for it.
Dependable Python dependency administration
One of many largest challenges for our customers to put in writing and construct Spark utility code is the battle of managing dependencies reliably, particularly for PySpark functions. Most of our ML-related Spark functions are constructed with PySpark. With our earlier Spark service vendor, the one supported option to handle Python dependencies was by way of a wheel file. Regardless of its recognition, wheel-based dependency administration is fragile. The next determine reveals two forms of reliability points confronted with wheel-based dependency administration:
- Unpinned direct dependency – If the .whl file doesn’t pinpoint the model of a sure direct dependency, Pandas on this instance, it is going to at all times pull the newest model from upstream, which can probably include a breaking change and take down our Spark functions.
- Unpinned transitive dependency – The second sort of reliability concern is extra out of our management. Despite the fact that we pinned the direct dependency model when constructing the .whl file, the direct dependency itself might miss pinpointing the transitive dependencies’ variations (MLFlow on this instance). The direct dependency on this case at all times pulls the newest variations of those transitive dependencies that probably include breaking adjustments and should take down our pipelines.

The opposite concern we encountered was the pointless set up of all Python packages referred by the wheel recordsdata for each Spark utility initialization. With our earlier setup, we wanted to run the set up script to put in wheel recordsdata for each Spark utility upon beginning even when there isn’t a dependency change. This set up prolongs the Spark utility begin time from 3–4 minutes to at the very least 7–8 minutes. The slowdown is irritating particularly when our engineers are actively iterating over adjustments.
Shifting to EMR on EKS allows us to make use of pex (Python EXecutable) to handle Python dependencies. A .pex file packs all dependencies (together with direct and transitive) of a PySpark utility in an executable Python atmosphere within the spirit of digital environments.
The next determine reveals the file construction after changing the wheel file illustrated earlier to a .pex file. In comparison with the wheel-based workflow, we don’t have transitive dependency pulling or auto-latest model fetching anymore. All variations of dependencies are fastened as x.y.z, a.b.c, and so forth when constructing the .pex file. Given a .pex file, all dependencies are fastened in order that we don’t endure from the slowness or fragility points in a wheel-based dependency administration anymore. The price of constructing a .pex file is a one-off price, too.

Dependable and environment friendly useful resource provisioning
Useful resource provisioning is the method for the Spark platform to get computing assets for Spark functions, and is the muse for the entire Spark platform. When constructing a Spark platform within the cloud, utilizing Spot Cases for price optimization makes useful resource provisioning much more difficult. Spot Cases are spare compute capability obtainable to you at a financial savings of as much as 90% off in comparison with On-Demand costs. Nonetheless, when the demand for sure occasion varieties grows instantly, Spot Occasion termination can occur to prioritize assembly these calls for. Due to these terminations, we noticed a number of challenges in our earlier model of Spark platform:
- Unreliable Spark functions – When the Spot Occasion termination occurred, the runtime of Spark functions acquired extended considerably as a result of retried compute phases.
- Compromised developer expertise – The unstable provide of Spot Cases triggered frustration amongst engineers and slowed our improvement iterations due to the unpredictable efficiency and low success charge of Spark functions.
- Costly infrastructure invoice – Our cloud infrastructure invoice elevated considerably as a result of retry of jobs. We had to purchase dearer Amazon Elastic Compute Cloud (Amazon EC2) cases with greater capability and run in a number of Availability Zones to mitigate points however in flip paid for the excessive price of cross-Availability Zone site visitors.
Spark Service Suppliers (SSPs) like EMR on EKS or different third-party software program merchandise function the intermediate between customers and Spot Occasion swimming pools, and play a key function to make sure the ample provide of Spot Cases. As proven within the following determine, customers launch Spark jobs with job orchestrators, notebooks, or providers by way of SSPs. The SSP implements their inside performance to entry the unused cases within the Spot Occasion pool in cloud providers like AWS. The most effective practices of utilizing Spot Cases is to diversify occasion varieties (for extra data, see Value Optimization utilizing EC2 Spot Cases). Particularly, there are two key options for a SSP to realize occasion diversification:
- The SSP ought to be capable to entry all forms of cases within the Spot Occasion pool in AWS
- The SSP ought to present performance for customers to make use of as many occasion varieties as doable when launching Spark functions
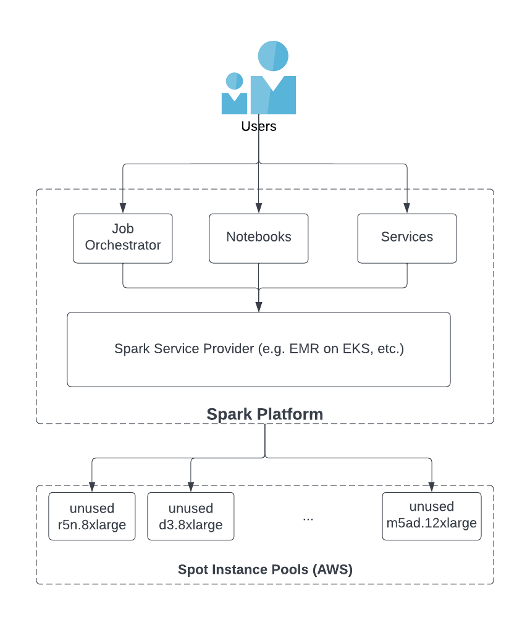
Our final SSP doesn’t present the anticipated resolution to those two factors. They solely assist a restricted set of Spot Occasion varieties and by default, permit solely a single Spot Occasion sort to be chosen when launching Spark jobs. Because of this, every Spark utility solely runs with a small capability of Spot Cases and is susceptible to Spot Occasion terminations.
EMR on EKS makes use of Amazon Elastic Kubernetes Service (Amazon EKS) for accessing Spot Cases in AWS. Amazon EKS helps all obtainable EC2 occasion varieties, bringing a a lot greater capability pool to us. We use the options of Amazon EKS managed node teams and node selectors and taints to assign every Spark utility to a node group that’s product of a number of occasion varieties. After transferring to EMR on EKS, we noticed the next advantages:
- Spot Occasion termination was much less frequent and our Spark functions’ runtime grew to become shorter and stayed secure.
- Engineers have been capable of iterate sooner as they noticed enchancment within the predictability of utility behaviors.
- The infrastructure prices dropped considerably as a result of we not wanted pricey workarounds and, concurrently, we had a complicated choice of cases in every node group of Amazon EKS. We have been capable of save roughly 50% of computing prices with out the workarounds like operating in a number of Availability Zones and concurrently present the anticipated stage of reliability.
Clean debugging expertise
An infrastructure that helps engineers conveniently debugging the Spark utility is crucial to shut the loop of our engineering workflow. Apache Spark makes use of occasion logs to document the actions of a Spark utility, comparable to process begin and end. These occasions are formatted in JSON and are utilized by SHS to rerender the UI of Spark functions. Engineers can entry SHS to debug process failure causes or efficiency points.
The foremost problem for engineers in SafeGraph was the scalability concern in SHS. As proven within the left a part of the next determine, our earlier SSP compelled all engineers to share the identical SHS occasion. Because of this, SHS was underneath intense useful resource strain as a consequence of many engineers accessing on the similar time for debugging their functions, or if a Spark utility had a big occasion log to be rendered. Previous to transferring to EMR on EKS, we incessantly skilled both slowness of SHS or SHS crashed fully.
As proven within the following determine, for each request to view Spark historical past UI, EMR on EKS begins an unbiased SHS occasion container in an AWS-managed atmosphere. The advantage of this structure is two-fold:
- Totally different customers and Spark functions received’t compete for SHS assets anymore. Due to this fact, we by no means expertise slowness or crashes of SHS.
- All SHS containers are managed by AWS; customers don’t want pay extra monetary or operational prices to benefit from the scalable structure.

Manageable Spark platform
As proven within the engineering workflow, constructing a Spark platform just isn’t a one-off effort, and platform groups have to handle the Spark platform and hold optimizing every step within the engineer improvement workflow. The function of the SSP ought to present the best amenities to ease operational burden as a lot as doable. Though there are various forms of operational duties, we concentrate on two of them on this publish: computing useful resource SKU administration and Spark distro model administration.
Computing useful resource SKU administration refers back to the design and course of for a Spark platform to permit customers to decide on totally different sizes of computing cases. Such a design and course of would largely depend on the related performance applied from SSPs.
The next determine reveals the SKU administration with our earlier SSP.

The next determine reveals SKU administration with EMR on EKS.

With our earlier SSP, job configuration solely allowed explicitly specifying a single Spot Occasion sort, and if that sort ran out of Spot capability, the job switched to On-Demand or fell into reliability points. This left platform engineers with the selection of adjusting the settings throughout the fleet of Spark jobs or risking undesirable surprises for his or her funds and value of products bought.
EMR on EKS makes it a lot simpler for the platform crew to handle computing SKUs. In SafeGraph, we embedded a Spark service consumer between customers and EMR on EKS. The Spark service consumer exposes solely totally different tiers of assets to customers (comparable to small, medium, and huge). Every tier is mapped to a sure node group configured in Amazon EKS. This design brings the next advantages:
- Within the case of costs and capability adjustments, it’s straightforward for us to replace configurations in node teams and hold it abstracted from customers. Customers don’t change something, and even really feel it, and proceed to benefit from the secure useful resource provisioning whereas we hold prices and operational overhead as little as doable.
- When selecting the best assets for the Spark utility, end-users don’t have to do any guess work as a result of it’s straightforward to decide on with simplified configuration.
Improved Spark distro launch administration is the opposite profit we acquire from EMR on EKS. Previous to utilizing EMR on EKS, we suffered from the non-transparent launch of Spark distro in our SSP. Each 1–2 months, there’s a new patched model of Spark distro launched to customers. These variations are all uncovered to customers by way of their UI. This resulted in engineers selecting numerous variations of distro, a few of which hadn’t been examined with our inside instruments. It considerably elevated the breaking charge of our pipelines, inside techniques, and the assist burden of platform groups. We anticipate that the chance from releases of Spark distros ought to be minimal and clear to customers with an EMR on EKS structure.
EMR on EKS follows the perfect practices with a secure base Docker picture containing a hard and fast model of Spark distro. For any change of Spark distro, we’ve to explicitly rebuild and roll out the Docker picture. With EMR on EKS, we will hold a brand new model of Spark distro hidden from customers earlier than testing it with our inside toolings and techniques and make a proper launch.
Conclusion
On this publish, we shared our journey constructing a Spark platform on high of EMR on EKS. EMR on EKS because the SSP serves as a robust basis of our Spark platform. With EMR on EKS, we have been capable of resolve challenges starting from dependency administration, useful resource provisioning, and debugging expertise, and likewise considerably scale back our computing price by 50% as a consequence of greater availability of Spot Occasion varieties and sizes.
We hope this publish might share some insights to the neighborhood when selecting the best SSP for your enterprise. Study extra about EMR on EKS, together with advantages, options, and methods to get began.
In regards to the Authors
 Nan Zhu is the Tech Lead Supervisor of the platform crew in SafeGraph. He leads the crew to construct a broad vary of infrastructure and inside toolings to enhance the reliability, effectivity and productiveness of the SafeGraph engineering course of, e.g. inside Spark ecosystem, metrics retailer and CI/CD for giant mono repos, and so on. He’s additionally concerned in a number of open supply tasks like Apache Spark, Apache Iceberg, Gluten, and so on.
Nan Zhu is the Tech Lead Supervisor of the platform crew in SafeGraph. He leads the crew to construct a broad vary of infrastructure and inside toolings to enhance the reliability, effectivity and productiveness of the SafeGraph engineering course of, e.g. inside Spark ecosystem, metrics retailer and CI/CD for giant mono repos, and so on. He’s additionally concerned in a number of open supply tasks like Apache Spark, Apache Iceberg, Gluten, and so on.
 Dave Thibault is a Sr. Options Architect serving AWS’s unbiased software program vendor (ISV) prospects. He’s captivated with constructing with serverless applied sciences, machine studying, and accelerating his AWS prospects’ enterprise success. Previous to becoming a member of AWS, Dave spent 17 years in life sciences corporations doing IT and informatics for analysis, improvement, and scientific manufacturing teams. He additionally enjoys snowboarding, plein air oil portray, and spending time together with his household.
Dave Thibault is a Sr. Options Architect serving AWS’s unbiased software program vendor (ISV) prospects. He’s captivated with constructing with serverless applied sciences, machine studying, and accelerating his AWS prospects’ enterprise success. Previous to becoming a member of AWS, Dave spent 17 years in life sciences corporations doing IT and informatics for analysis, improvement, and scientific manufacturing teams. He additionally enjoys snowboarding, plein air oil portray, and spending time together with his household.





