
Amazon QuickSight Q makes use of machine studying (ML) and pure language expertise to empower you to ask enterprise questions on your information and get solutions immediately. You possibly can merely enter your questions (for instance, “What’s the year-over-year gross sales development?”) and get the reply in seconds within the type of a QuickSight visible.
Some enterprise questions can’t be answered by means of current enterprise intelligence (BI) dashboards. It could take days or even weeks for the BI staff to accommodate these wants and refine their resolution. As a result of Q doesn’t rely on prebuilt dashboards or studies to reply questions, it removes the necessity for BI groups to create or replace dashboards each time a brand new enterprise query arises. You possibly can ask questions and obtain solutions within the type of visuals in seconds immediately from inside QuickSight or from internet purposes and portals. Q empowers each enterprise consumer to self-serve and get insights sooner, no matter their background or skillset.
On this submit, we stroll you thru the steps to configure Q utilizing an Olympic Video games public dataset and exhibit how an end-user can ask easy questions immediately from Q in an interactive method and obtain solutions in seconds.
You possibly can interactively play with the Olympic dashboard and Q search bar within the following interactive demo.

Resolution overview
We use Olympic video games public datasets to configure a Q matter and focus on ideas and tips on make additional configurations on the subject that allow Q to supply immediate solutions utilizing ML-powered, pure language question (NLQ) capabilities that empower you to ask questions on information utilizing on a regular basis enterprise language.
The video from Information Con LA gives a high-level demonstration of the capabilities coated on this submit.
Moreover, we focus on the next:
- Finest practices for information modeling of a Q matter
- carry out information cleaning utilizing AWS Glue DataBrew, SQL, or an Amazon SageMaker Jupyter pocket book on datasets to construct a Q matter
We use a number of publicly obtainable datasets from Kaggle. The datasets have historic details about athletes, together with identify, ID, age, weight, nation, and medals.
We use the 2020 Olympic datasets and historic information. We additionally use the datasets Introduction of Ladies Olympic Sport and Ladies of Olympic Video games to find out the participation of ladies athletes in Olympics and uncover tendencies. The QuickSight datasets created utilizing these public information recordsdata are added to a Q matter, as proven within the following screenshot. We offer particulars on creating QuickSight datasets later on this submit.

Conditions
To comply with together with the answer introduced on this submit, you will need to have entry to the next:
Create resolution assets
The general public datasets in Kaggle can’t be immediately utilized to create a Q matter. We’ve got already cleansed the uncooked information and have supplied the cleansed datasets within the GitHub repo. In case you are fascinated with studying extra about information cleaning, we mentioned three completely different information cleaning strategies on the finish of this submit.
To create your assets, full the next steps:
- Create an S3 bucket referred to as
olympicsdata. - Create a folder for every information file, as proven within the following screenshot.

- Add the information recordsdata from the GitHub repo into their respective folders.
- Deploy the supplied CloudFormation template and supply the required info.
The template creates an Athena database and tables, as proven within the following screenshot.

The template additionally creates the QuickSight information supply athena-olympics and datasets.

Create datasets in QuickSight
To construct the Q matter, we have to mix the datasets, as a result of every desk comprises solely partial information. Becoming a member of these tables helps reply questions throughout all of the options of the 2020 Olympics.
We create the Olympics 2021 dataset by becoming a member of the tables Medals_athletes_2021, Athletes_full_2021, Coach_full_2021, and Tech_official_2021.
The next screenshot exhibits the joins for our full dataset.

Medals_athletes_2021 is the primary desk, with the next be part of situations:
- Left outer be part of
athletes_full_2021onathlete_name,discipline_code, andcountry_code - Left outer be part of
coach_full_2021on nation, self-discipline, and occasion - Left outer be part of
tech_official_2021on self-discipline
Lastly, we have now the next datasets that we use for our Q matter:
- Olympics 2021 Particulars
- Medals 2021
- Olympics Historical past (created utilizing the
Olympicsdesk) - Introduction of Ladies Olympics Sports activities
- Ladies within the Olympic Motion
Create a Q matter
Matters are collections of a number of datasets that symbolize a topic space that your enterprise customers can ask questions on. In QuickSight, you possibly can create and handle subjects on the Matters web page. Once you create a subject, your enterprise customers can ask questions on it within the Q search bar.
Once you create subjects in Q, you possibly can add a number of datasets to them after which configure all of the fields within the datasets to make them pure language-friendly. This permits Q to supply your enterprise customers with the right visualizations and solutions to their questions.
The next are information modeling greatest practices for Q subjects:
- Cut back the variety of datasets by consolidating the information. Any given query can solely hit one information set, so solely embrace a number of datasets if they’re associated sufficient to be a part of the identical matter, however distinct sufficient that you would be able to ask a query towards them independently.
- For naming conventions, present a significant identify or alias (synonym) of a discipline to permit the end-user to simply question it.
- If a discipline seems in several datasets, ensure that this discipline has the identical identify throughout completely different datasets.
- Validate information consistency. For instance, the full worth of a metric that aggregates from completely different datasets must be constant.
- For fields that don’t request on-the-fly calculations, for instance, metrics with distributive features (sum, max, min, and so forth), push down the calculation into an information warehouse.
- For fields that request on-the-fly calculations, create the calculated discipline within the QuickSight dataset or Q matter. If different subjects or dashboards would possibly reuse the identical discipline, create it within the datasets.
To create a subject, full the next steps:
- On the QuickSight console, select Matters within the navigation pane.
- Select New matter.

- For Subject identify, enter a reputation.
- For Description, enter an outline.
- Select Save.

- On the Add information to matter web page that opens, select Datasets, after which choose the datasets that we created within the earlier part.
- Select Add information to create the subject.
Improve the subject
On this part, we focus on varied methods that you would be able to improve the subject.
Add calculated fields to a subject dataset
You possibly can add new fields to a dataset in a subject by creating calculated fields.
For instance, we have now the column Age in our Olympics dataset. We will create a calculated discipline to group age into completely different ranges utilizing the ifelse perform. This calculated discipline might help us ask a query like “What number of athletes for every age group?”
- Select Add calculated discipline.
- Within the calculation editor, enter the next syntax:
- Identify the calculated discipline
Age Teams. - Select Save.
The calculated discipline is added to the listing of fields within the matter.
Add filters to a subject dataset
Let’s say lot of study is predicted on the dataset for the summer time season. We will add a filter to permit for simple collection of this worth. Moreover, if we wish to permit evaluation towards information for the summer time season solely, we are able to select to all the time apply this filter or apply it because the default selection, however permit customers to ask questions on different seasons as nicely.
- Select Add filter.
- For Identify, enter
Summer time. - Select the
Ladies within the Olympic Motiondataset. - Select the
Olympics Seasondiscipline. - Select Customized filter listing for Filter kind and set the rule as embrace.
- Enter Summer time underneath Values.
- Select Apply all the time, except a query leads to an express filter from the dataset.
- Select Save.
The filter is added to the listing of fields within the matter.
Add named entities to a subject dataset
We will outline named entities if we have to present customers a mixture of fields. For instance, when somebody asks for participant particulars, it is sensible to indicate them participant identify, age, nation, sport, and medal. We will make this occur by defining a named entity.
- Select Add named entity.
- Select the
Olympicsdataset. - Enter
Participant Profilefor Identify. - Enter
Data of Participantfor Description. - Select Add discipline.
- Select Participant Identify from the listing.
- Select Add discipline once more and add the fields
Age,Nations,Sport, andMedal.
The fields listed are the order they seem in solutions. To maneuver a discipline, select the six dots subsequent to the identify and drag and drop the sector to the order that you really want. - Select Save.
The named entity is added to the listing of fields within the matter.
Make Q subjects pure language-friendly
To assist Q interpret your information and higher reply your readers’ questions, present as a lot details about your datasets and their related fields as potential.
To make the subject extra pure language-friendly, use the next procedures.
Rename fields
You may make your discipline names extra user-friendly in your subjects by renaming them and including descriptions.
Q makes use of discipline names to know the fields and hyperlink them to phrases in your readers’ questions. When your discipline names are user-friendly, it’s simpler for Q to attract hyperlinks between the information and a reader’s query. These pleasant names are additionally introduced to readers as a part of the reply to their query to supply extra context.
Let’s rename the beginning date discipline from the athlete dataset as Athlete Start Date. As a result of we have now a number of beginning date fields within the subjects for coach, athlete, and tech roles, renaming the athletes’ beginning date discipline helps Q simply hyperlink to the information discipline once we ask questions concerning athletes’ beginning dates.
- On the Fields web page, select the down arrow at far proper of the
Start Datediscipline to broaden it. - Select the pencil icon subsequent to the sector identify.
- Rename the sector to
Athlete Start Date.

Add synonyms to fields in a subject
Even if you happen to replace your discipline names to be user-friendly and supply an outline for them, your readers would possibly nonetheless use completely different names to consult with them. For instance, a participant identify discipline is likely to be known as participant, gamers, or sportsman in your reader’s questions.
To assist Q make sense of those phrases and map them to the right fields, you possibly can add a number of synonyms to your fields. Doing this improves Q’s accuracy.
- On the Fields web page, underneath Synonyms, select the pencil icon for
Participant Identify. - Enter
participantandsportsmanas synonyms.
Add synonyms to discipline values
Like we did for discipline names, we are able to add synonyms for class values as nicely.
- Select the
Genderdiscipline’s row to broaden it. - Select Configure worth synonyms, then select Add.
- Select the pencil icon subsequent to the F worth.
- Add the synonym
Feminine. - Repeat these steps so as to add the synonym
MaleforM. - Select Achieved.

Assign discipline roles
Each discipline in your dataset is both a dimension or a measure. Realizing whether or not a discipline is a dimension or a measure determines what operations Q can and might’t carry out on a discipline.
For instance, setting the sector Age as a dimension implies that Q doesn’t attempt to mixture it because it does measures.
- On the Fields web page, broaden the Age discipline.
- For Function, select Dimension.

Set discipline aggregations
Setting discipline aggregations tells Q which perform ought to or shouldn’t be used when these fields are aggregated throughout a number of rows. You possibly can set a default aggregation for a discipline, and specify aggregations that aren’t allowed.
A default aggregation is the aggregation that’s utilized when there’s no express aggregation perform talked about or recognized in a reader’s query. For instance, let’s ask Q “Present whole variety of occasions.” On this case, Q makes use of the sector Complete Occasions, which has a default aggregation of Sum, to reply the query.
- On the Fields web page, broaden the Complete Occasions discipline.
- For Default aggregation, select Sum.
- For Not allowed aggregation, select Common.

Specify discipline semantic sorts
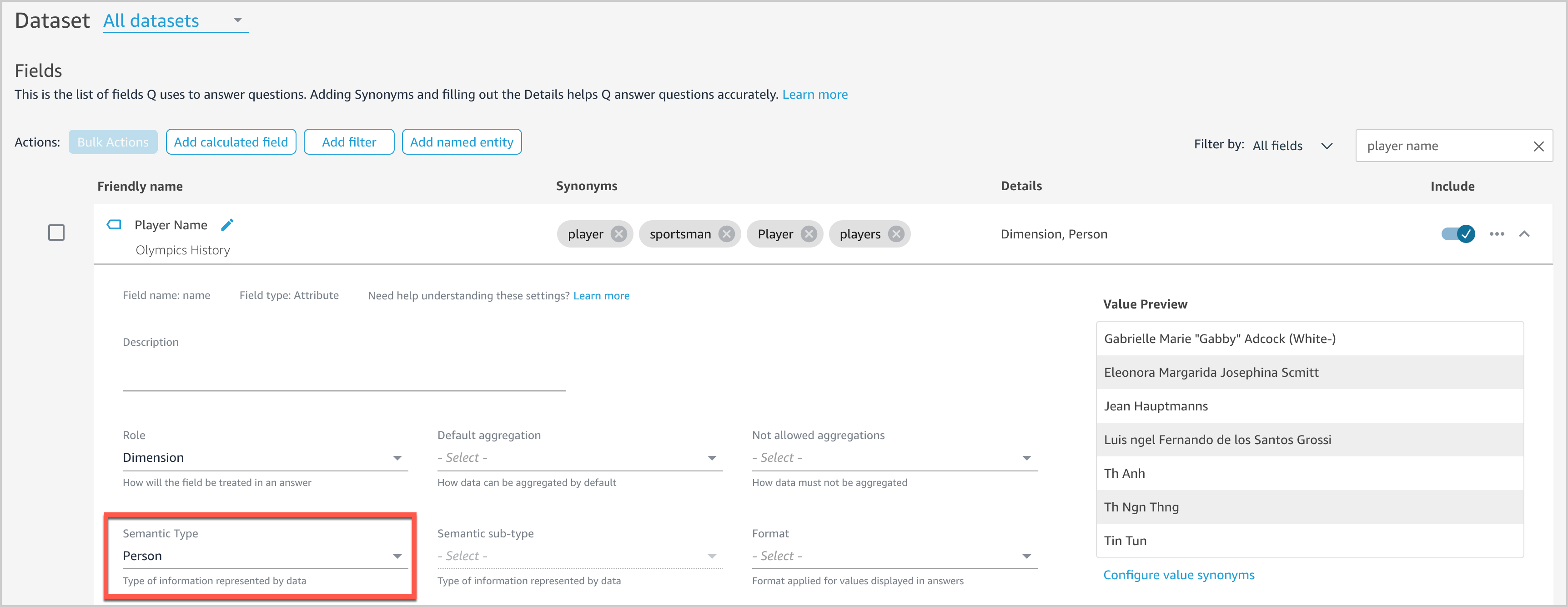
Offering extra particulars on the sector context will assist Q reply extra pure language questions. For instance, customers would possibly ask “Who gained essentially the most medals?” We haven’t set any semantic info for any fields in our dataset but, so Q doesn’t know what fields to affiliate with “who.” Let’s see how we are able to allow Q to deal with this query.
- On the Fields web page, broaden the
Participant Identifydiscipline. - For Semantic Kind, select Individual.
This permits Q to floor Participant Identify as an possibility when answering “who”-based questions.
Exclude unused or pointless fields
Fields from all included datasets are displayed by default. Nevertheless, we have now a couple of fields like Quick identify of Nation, URL Coach Full 2021, and URL Tech Official 2021 that we don’t want in our matter. We will exclude pointless fields from the subject to stop them from exhibiting up in outcomes by selecting the slider subsequent to every discipline.

Ask questions with Q
After we create and configure our matter, we are able to now work together with Q by getting into questions within the Q search bar.
For instance, let’s enter present whole medals by nation. Q presents a solution to your query as a visible.
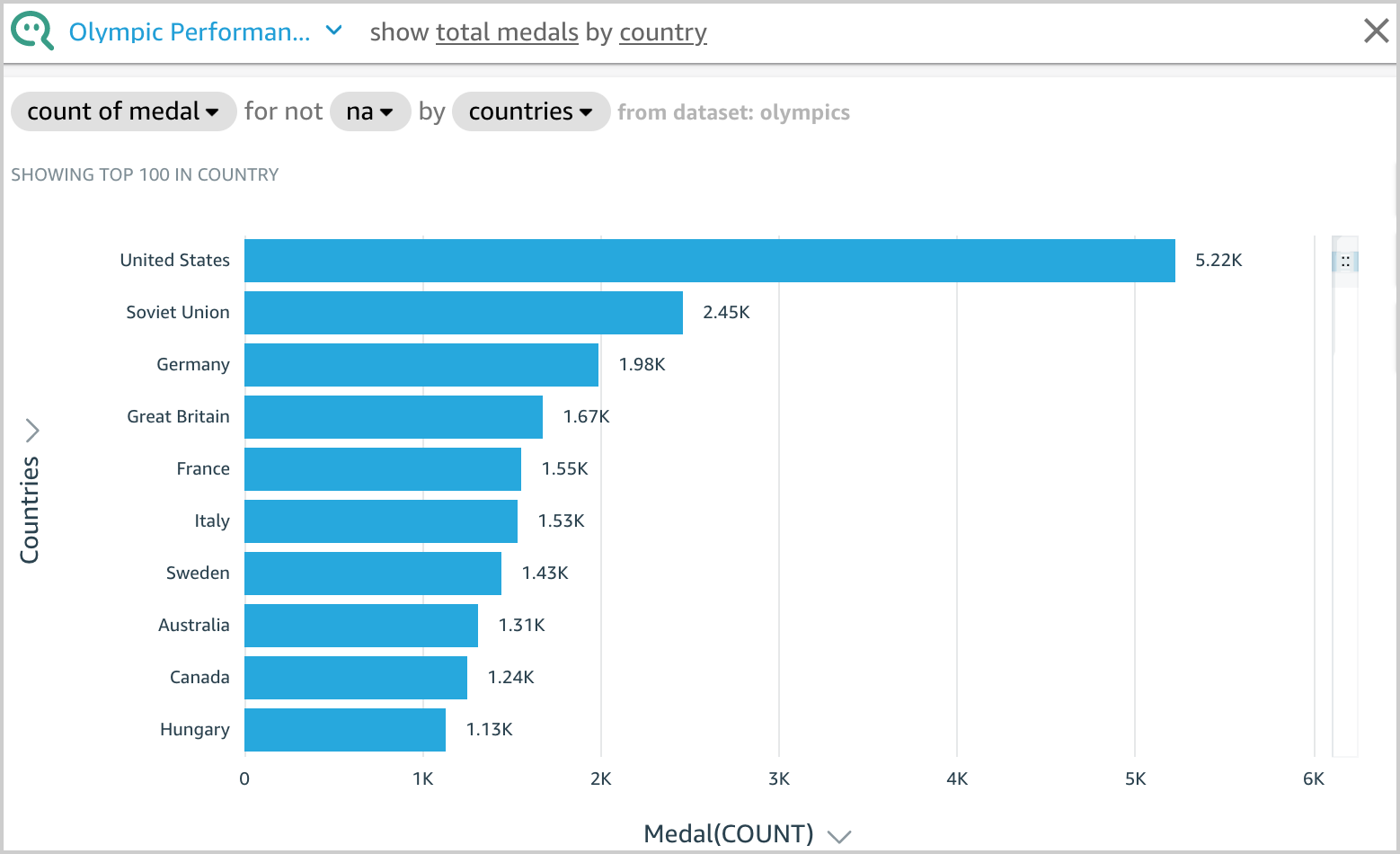
You possibly can see how Q interpreted your query within the description on the visible’s higher left. Right here you possibly can see the fields, aggregations, matter filters, and datasets used to reply the query. The subject filter na is utilized on the Medal attribute, which excludes na values from the aggregation. For extra info on matter filters, see Including filters to a subject dataset.

Q shows the outcomes utilizing the visible kind greatest suited to convey the data. Nevertheless, Q additionally provides you the flexibleness to view leads to different visible sorts by selecting the Visible icon.
One other instance, let’s enter who's the oldest participant in basketball. Q presents a solution to your query as a visible.

Typically Q won’t interpret your query the best way you needed. When this occurs, you possibly can present suggestions on the reply or make options for corrections to the reply. For extra details about offering reply suggestions, see Offering suggestions about QuickSight Q subjects. For extra details about correcting solutions, see Correcting incorrect solutions supplied by Amazon QuickSight Q.
Conclusion
On this submit, we confirmed you configure Q utilizing an Olympic video games public dataset and so end-users can ask easy questions immediately from Q in an interactive method and obtain solutions in seconds. If in case you have any suggestions or questions, please go away them within the feedback part.
Appendix 1: Forms of questions supported by Q
Let’s take a look at samples of every query kind that Q can reply utilizing the subject created earlier on this submit.
Attempt the next questions or your individual questions and proceed enhancing the subject to enhance accuracy of responses.
| Query Kind | Instance |
| Dimensional Group Bys | present whole medals by nation |
| Dimensional Filters (Embrace) | present whole medals for u.s.a. |
| Date Group Bys | present yearly development of ladies contributors |
| Multi Metrics | variety of girls occasions in comparison with whole occasions |
| KPI-Primarily based Interval over Durations (PoPs) | what number of girls contributors in 2018 over 2016 |
| Relative Date Filters | present whole medals for u.s.a. within the final 5 years |
| Time Vary Filters | listing of ladies sports activities launched since 2016 |
| Prime/Backside Filter | present me the highest 3 participant with gold medal |
| Kind Order | present high 3 international locations with most medals |
| Mixture Metrics Filter | present groups that gained greater than 50 medals |
| Listing Questions | listing the ladies sports activities by yr by which they’re launched |
| OR filters | Present participant who obtained gold or silver medal |
| P.c of Complete | Share of gamers by nation |
| The place Questions | the place are essentially the most variety of medals |
| When Questions | when girls volleyball launched into olympic video games |
| Who Questions | who’s the oldest participant in basketball |
| Exclude Questions | present international locations with highest medals excluding u.s.a. |
Appendix 2: Information cleaning
On this part, we offer three choices for information cleaning: SQL, DataBrew, and Python.
Choice 1: SQL
For our first possibility, we focus on create Athena tables on the downloaded Excel or CSV recordsdata after which carry out the information cleaning utilizing SQL. This feature is appropriate for many who use Athena tables as an information supply for QuickSight datasets and are comfy utilizing SQL.
The SQL queries to create Athena tables can be found within the GitHub repo. In these queries, we carry out information cleaning by renaming, altering the information kind of some columns, in addition to eradicating the duplicates of rows. Correct naming conventions and correct information sorts assist Q effectively hyperlink the inquiries to the information fields and supply correct solutions.
Use the next pattern DDL question to create an Athena desk for women_introduction_to_olympics:
In our information recordsdata, there are few columns which can be widespread throughout a couple of dataset which have completely different column names. For instance, gender is obtainable as gender or intercourse, nation is obtainable as nation or staff or staff/noc, and individual names have a job prefix in a single dataset however not in different datasets. We rename such columns utilizing SQL to take care of constant column names.
Moreover, we have to change different demographic columns like age, top, and weight to the INT information kind, in order that they don’t get imported as String.
The next columns from the information recordsdata have been reworked utilizing SQL.
| Information File | Unique Column | New Column |
| medals | Self-disciplineMedal_date (timestamp) |
SportMedal_date (date) |
| Athletes | identifygenderbirth_datebirth_placebirth_country |
athlete_nameathlete_genderathlete_birth_dateathlete_birth_placeathlete_birth_country |
| Coaches | identifygenderbirth_dateperform |
coach_namecoach_gendercoach_birth_datecoach_function |
| Athlete_events (historical past) | WorkforceNOCAge (String)Top (String)Weight (String) |
nationcountry_codeAge (Integer)Top (Integer)Weight (Integer) |
Choice 2: DataBrew
On this part, we focus on an information cleaning possibility utilizing DataBrew. DataBrew is a visible information preparation device that makes it simple to wash and put together information with no prior coding data. You possibly can immediately load the outcomes into an S3 bucket or load the information by importing an Excel or CSV file.
For our instance, we stroll you thru the steps to implement information cleaning on the medals_athletes_2021 dataset. You possibly can comply with the identical course of to carry out any needed information cleansing on different datasets as nicely.
Create a brand new dataset in DataBrew utilizing medals_athletes.csv after which create a DataBrew venture and implement the next recipes to cleanse the information within the medals_athletes_2021 dataset.
- Delete empty rows within the
athlete_namecolumn.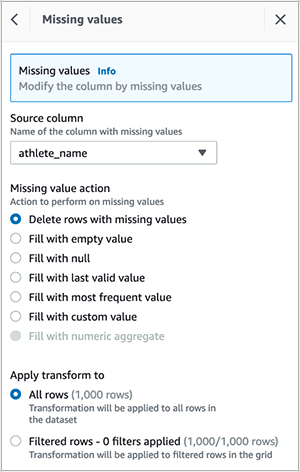
- Delete empty rows within the
medal_typecolumn.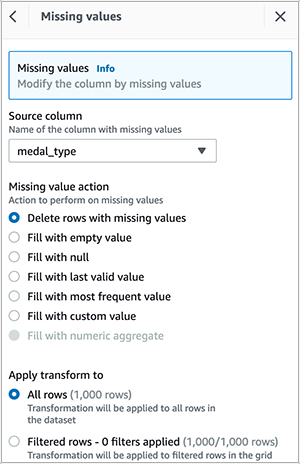
- Delete duplicate rows within the dataset.
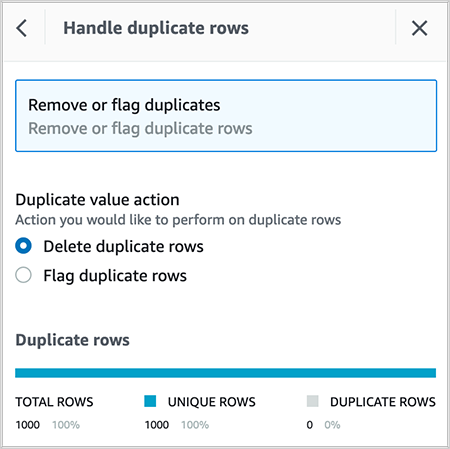
- Rename self-discipline to
Sport.
- Delete the column
discipline_code.
- Cut up the column
medal_typeon a single delimiter.
- Delete the column
medal_type_2, which was created because of step 6.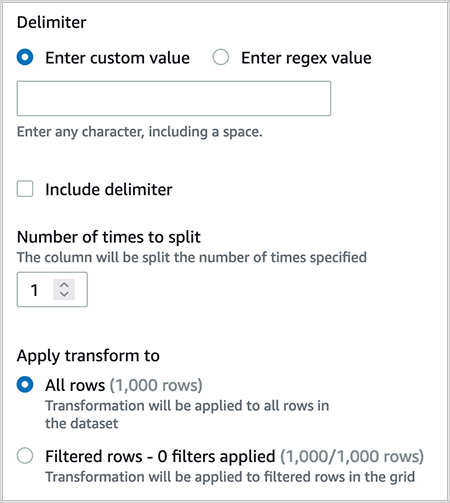
- Rename
medal_type_1tomedal_type.
- Change the information kind of column
medal_datefrom timestamp to date.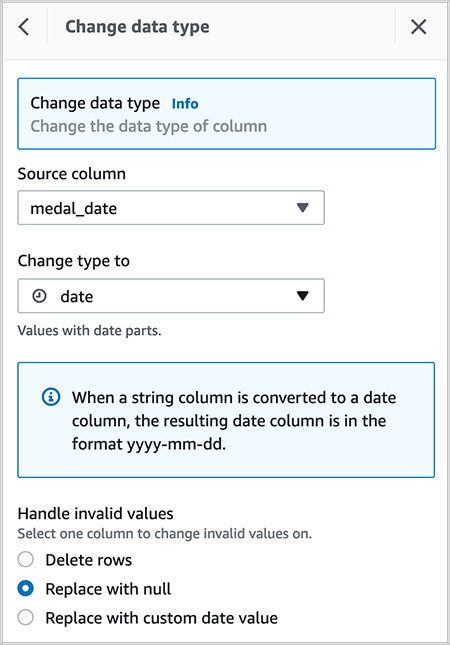
After you create the recipe, publish it and create a job to output the leads to your required vacation spot. You possibly can create QuickSight SPICE datasets by importing the cleaned CSV file.
Choice 3: Python
On this part, we focus on information cleaning utilizing NumPy and Pandas of Python on the medals_athletes_2021 dataset. You possibly can comply with the identical course of to carry out any needed information cleaning on different datasets as nicely. The pattern Python code is obtainable on GitHub. This feature is appropriate for somebody who’s comfy processing the information utilizing Python.
- Delete the column
discipline_code: - Rename the column self-discipline to sport:
You possibly can create QuickSight SPICE datasets by importing the cleansed CSV.
Appendix 3: Information cleaning and modeling within the QuickSight information preparation layer
On this part, we focus on another technique of information cleaning that you would be able to carry out from the QuickSight information preparation layer, along with the strategies mentioned beforehand. Utilizing SQL, DataBrew, or Python have benefits as a result of you possibly can put together and clear the information outdoors QuickSight so different AWS providers can use the cleansed outcomes. Moreover, you possibly can automate the scripts. Nevertheless, Q authors should be taught different instruments and programming languages to benefit from these choices.
Cleaning information within the QuickSight dataset preparation stage permits non-technical Q authors to construct the appliance finish to finish in QuickSight with a codeless technique.
The QuickSight dataset shops any information preparation completed on the information, in order that the ready information could be reused in a number of analyses and subjects.
We’ve got supplied a couple of examples for information cleaning within the QuickSight information preparation layer.
Change a discipline identify
Let’s change the identify information discipline from Athletes_full_2021 to athlete_name.
- Within the information preview pane, select the edit icon on the sector that you simply wish to change.
- For Identify, enter a brand new identify.
- Select Apply.

Change a discipline information kind
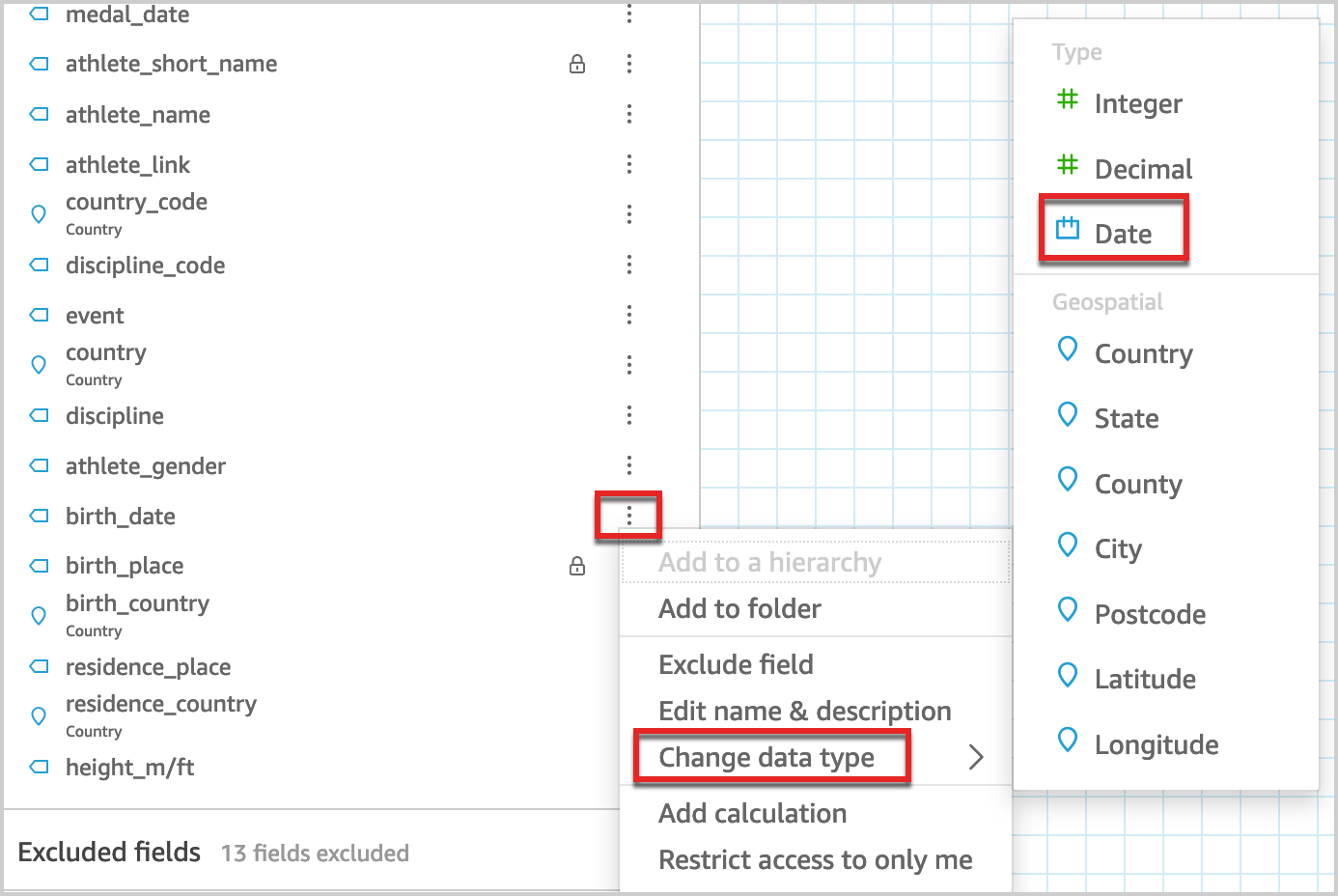
You possibly can change the information kind of any discipline from the information supply within the QuickSight information preparation layer utilizing the next process.
- Within the information preview pane, select the edit icon on the sector you wish to change (for instance,
birth_date). - Select Change information kind and select Date.
This converts the string discipline to a date discipline.
Appendix 4: Details about the tables
The next desk illustrates the scope of every desk within the dataset.
In regards to the authors
 Ying Wang is a Supervisor of Software program Growth Engineer. She has 12 years expertise in information analytics and information science. In her information architect life, she helped buyer on enterprise information structure options to scale their information analytics within the cloud. At present, she helps buyer to unlock the ability of Information with QuickSight from engineering/product by delivering new options.
Ying Wang is a Supervisor of Software program Growth Engineer. She has 12 years expertise in information analytics and information science. In her information architect life, she helped buyer on enterprise information structure options to scale their information analytics within the cloud. At present, she helps buyer to unlock the ability of Information with QuickSight from engineering/product by delivering new options.
 Ginni Malik is a Information & ML Engineer with AWS Skilled Providers. She assists clients by architecting enterprise degree information lake options to scale their information analytics within the cloud. She is a journey fanatic and likes to run half-marathons.
Ginni Malik is a Information & ML Engineer with AWS Skilled Providers. She assists clients by architecting enterprise degree information lake options to scale their information analytics within the cloud. She is a journey fanatic and likes to run half-marathons.
 Niharika Katnapally is a QuickSight Enterprise Intelligence Engineer with AWS Skilled Providers. She assists clients by creating QuickSight dashboards to assist them achieve insights into their information and make information pushed enterprise selections.
Niharika Katnapally is a QuickSight Enterprise Intelligence Engineer with AWS Skilled Providers. She assists clients by creating QuickSight dashboards to assist them achieve insights into their information and make information pushed enterprise selections.





