Many AWS prospects use Amazon Elastic Kubernetes Service (Amazon EKS) so as to make the most of Kubernetes with out the burden of managing the Kubernetes management airplane. With Kubernetes, you possibly can centrally handle your workloads and provide directors a multi-tenant setting the place they will create, replace, scale, and safe workloads utilizing a single API. Kubernetes additionally means that you can enhance useful resource utilization, cut back price, and simplify infrastructure administration to help completely different software deployments. This mannequin is helpful for these operating Apache Spark workloads, for a number of causes. For instance, it means that you can have a number of Spark environments operating concurrently with completely different configurations and dependencies which can be segregated from one another via Kubernetes multi-tenancy options. As well as, the identical cluster can be utilized for numerous workloads like machine studying (ML), host functions, knowledge streaming and thereby lowering operational overhead of managing a number of clusters.
AWS provides Amazon EMR on EKS, a managed service that lets you run your Apache Spark workloads on Amazon EKS. This service makes use of the Amazon EMR runtime for Apache Spark, which will increase the efficiency of your Spark jobs in order that they run quicker and price much less. If you run Spark jobs on EMR on EKS and never on self-managed Apache Spark on Kubernetes, you possibly can make the most of automated provisioning, scaling, quicker runtimes, and the event and debugging instruments that Amazon EMR offers
On this publish, we present the right way to configure and run EMR on EKS in a multi-tenant EKS cluster that may utilized by your numerous groups. We deal with multi-tenancy via 4 matters: community, useful resource administration, price administration, and safety.
Ideas
All through this publish, we use terminology that’s both particular to EMR on EKS, Spark, or Kubernetes:
- Multi-tenancy – Multi-tenancy in Kubernetes can are available in three types: arduous multi-tenancy, delicate multi-tenancy and sole multi-tenancy. Laborious multi-tenancy means every enterprise unit or group of functions will get a devoted Kubernetes; there is no such thing as a sharing of the management airplane. This mannequin is out of scope for this publish. Smooth multi-tenancy is the place pods would possibly share the identical underlying compute useful resource (node) and are logically separated utilizing Kubernetes constructs via namespaces, useful resource quotas, or community insurance policies. A second solution to obtain multi-tenancy in Kubernetes is to assign pods to particular nodes which can be pre-provisioned and allotted to a particular staff. On this case, we discuss sole multi-tenancy. Except your safety posture requires you to make use of arduous or sole multi-tenancy, you’ll wish to think about using delicate multi-tenancy for the next causes:
- Smooth multi-tenancy avoids underutilization of assets and waste of compute assets.
- There’s a restricted variety of managed node teams that can be utilized by Amazon EKS, so for big deployments, this restrict can rapidly develop into a limiting issue.
- In sole multi-tenancy there may be excessive likelihood of ghost nodes with no pods scheduled on them on account of misconfiguration as we drive pods into devoted nodes with label, taints and tolerance and anti-affinity guidelines.
- Namespace – Namespaces are core in Kubernetes and a pillar to implement delicate multi-tenancy. With namespaces, you possibly can divide the cluster into logical partitions. These partitions are then referenced in quotas, community insurance policies, service accounts, and different constructs that assist isolate environments in Kubernetes.
- Digital cluster – An EMR digital cluster is mapped to a Kubernetes namespace that Amazon EMR is registered with. Amazon EMR makes use of digital clusters to run jobs and host endpoints. A number of digital clusters may be backed by the identical bodily cluster. Nonetheless, every digital cluster maps to at least one namespace on an EKS cluster. Digital clusters don’t create any energetic assets that contribute to your invoice or require lifecycle administration outdoors the service.
- Pod template – In EMR on EKS, you possibly can present a pod template to manage pod placement, or outline a sidecar container. This pod template may be outlined for executor pods and driver pods, and saved in an Amazon Easy Storage Service (Amazon S3) bucket. The S3 areas are then submitted as a part of the applicationConfiguration object that’s a part of configurationOverrides, as outlined within the EMR on EKS job submission API.
Safety issues
On this part, we deal with safety from completely different angles. We first focus on the right way to defend IAM position that’s used for operating the job. Then deal with the right way to defend secrets and techniques use in jobs and at last we focus on how one can defend knowledge whereas it’s processed by Spark.
IAM position safety
A job submitted to EMR on EKS wants an AWS Id and Entry Administration (IAM) execution position to work together with AWS assets, for instance with Amazon S3 to get knowledge, with Amazon CloudWatch Logs to publish logs, or use an encryption key in AWS Key Administration Service (AWS KMS). It’s a finest follow in AWS to use least privilege for IAM roles. In Amazon EKS, that is achieved via IRSA (IAM Position for Service Accounts). This mechanism permits a pod to imagine an IAM position on the pod degree and never on the node degree, whereas utilizing short-term credentials which can be offered via the EKS OIDC.
IRSA creates a belief relationship between the EKS OIDC supplier and the IAM position. This methodology permits solely pods with a service account (annotated with an IAM position ARN) to imagine a job that has a belief coverage with the EKS OIDC supplier. Nonetheless, this isn’t sufficient, as a result of it might enable any pod with a service account inside the EKS cluster that’s annotated with a job ARN to imagine the execution position. This should be additional scoped down utilizing situations on the position belief coverage. This situation permits the assume position to occur provided that the calling service account is the one used for operating a job related to the digital cluster. The next code exhibits the construction of the situation so as to add to the belief coverage:
{
"Model": "2012-10-17",
"Assertion": [
{
"Effect": "Allow",
"Principal": {
"Federated": <OIDC provider ARN >
},
"Action": "sts:AssumeRoleWithWebIdentity"
"Condition": { "StringLike": { “<OIDC_PROVIDER>:sub": "system:serviceaccount:<NAMESPACE>:emr-containers-sa-*-*-<AWS_ACCOUNT_ID>-<BASE36_ENCODED_ROLE_NAME>”} }
}
]
}
To scope down the belief coverage utilizing the service account situation, it’s worthwhile to run the next the command with AWS CLI:
aws emr-containers update-role-trust-policy
–cluster-name cluster
–namespace namespace
–role-name iam_role_name_for_job_executionThe command will the add the service account that shall be utilized by the spark shopper, Jupyter Enterprise Gateway, Spark kernel, driver or executor. The service accounts identify have the next construction emr-containers-sa-*-*-<AWS_ACCOUNT_ID>-<BASE36_ENCODED_ROLE_NAME>.
Along with the position segregation supplied by IRSA, we suggest blocking entry to occasion metadata as a result of a pod can nonetheless inherit the rights of the occasion profile assigned to the employee node. For extra details about how one can block entry to metadata, seek advice from Prohibit entry to the occasion profile assigned to the employee node.
Secret safety
Someday a Spark job must devour knowledge saved in a database or from APIs. More often than not, these are protected with a password or entry key. The commonest solution to move these secrets and techniques is thru setting variables. Nonetheless, in a multi-tenant setting, this implies any person with entry to the Kubernetes API can doubtlessly entry the secrets and techniques within the setting variables if this entry isn’t scoped nicely to the namespaces the person has entry to.
To beat this problem, we suggest utilizing a Secrets and techniques retailer like AWS Secrets and techniques Supervisor that may be mounted via the Secret Retailer CSI Driver. The advantage of utilizing Secrets and techniques Supervisor is the flexibility to make use of IRSA and permit solely the position assumed by the pod entry to the given secret, thereby enhancing your safety posture. You’ll be able to seek advice from the finest practices information for pattern code displaying using Secrets and techniques Supervisor with EMR on EKS.
Spark knowledge encryption
When a Spark software is operating, the driving force and executors produce intermediate knowledge. This knowledge is written to the node native storage. Anybody who is ready to exec into the pods would have the ability to learn this knowledge. Spark helps encryption of this knowledge, and it may be enabled by passing --conf spark.io.encryption.enabled=true. As a result of this configuration provides efficiency penalty, we suggest enabling knowledge encryption just for workloads that retailer and entry extremely delicate knowledge and in untrusted environments.
Community issues
On this part we focus on the right way to handle networking inside the cluster in addition to outdoors the cluster. We first deal with how Spark deal with cross executors and driver communication and the right way to safe it. Then we focus on the right way to prohibit community visitors between pods within the EKS cluster and permit solely visitors destined to EMR on EKS. Final, we focus on the right way to prohibit visitors of executors and driver pods to exterior AWS service visitors utilizing safety teams.
Community encryption
The communication between the driving force and executor makes use of RPC protocol and isn’t encrypted. Beginning with Spark 3 within the Kubernetes backed cluster, Spark provides a mechanism to encrypt communication utilizing AES encryption.
The motive force generates a key and shares it with executors via the setting variable. As a result of the secret is shared via the setting variable, doubtlessly any person with entry to the Kubernetes API (kubectl) can learn the important thing. We suggest securing entry in order that solely licensed customers can have entry to the EMR digital cluster. As well as, it is best to arrange Kubernetes role-based entry management in such a means that the pod spec within the namespace the place the EMR digital cluster runs is granted to only some chosen service accounts. This methodology of passing secrets and techniques via the setting variable would change sooner or later with a proposal to make use of Kubernetes secrets and techniques.
To allow encryption, RPC authentication should even be enabled in your Spark configuration. To allow encryption in-transit in Spark, it is best to use the next parameters in your Spark config:
Notice that these are the minimal parameters to set; seek advice from Encryption from the whole checklist of parameters.
Moreover, making use of encryption in Spark has a damaging influence on processing pace. It’s best to solely apply it when there’s a compliance or regulation want.
Securing Community visitors inside the cluster
In Kubernetes, by default pods can talk over the community throughout completely different namespaces in the identical cluster. This conduct just isn’t at all times fascinating in a multi-tenant setting. In some cases, for instance in regulated industries, to be compliant you wish to implement strict management over the community and ship and obtain visitors solely from the namespace that you simply’re interacting with. For EMR on EKS, it might be the namespace related to the EMR digital cluster. Kubernetes provides constructs that help you implement community insurance policies and outline fine-grained management over the pod-to-pod communication. These insurance policies are carried out by the CNI plugin; in Amazon EKS, the default plugin could be the VPC CNI. A coverage is outlined as follows and is utilized with kubectl:
Form: NetworkPolicy
metadata:
identify: default-np-ns1
namespace: <EMR-VC-NAMESPACE>
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
ingress:
- from:
- namespaceSelector:
matchLabels:
nsname: <EMR-VC-NAMESPACE>
Community visitors outdoors the cluster
In Amazon EKS, once you deploy pods on Amazon Elastic Compute Cloud (Amazon EC2) cases, all of the pods use the safety group related to the node. This may be a difficulty in case your pods (executor pods) are accessing an information supply (particularly a database) that enables visitors primarily based on the supply safety group. Database servers usually prohibit community entry solely from the place they’re anticipating it. Within the case of a multi-tenant EKS cluster, this implies pods from different groups that shouldn’t have entry to the database servers, would have the ability to ship visitors to it.
To beat this problem, you should utilize safety teams for pods. This characteristic means that you can assign a particular safety group to your pods, thereby controlling the community visitors to your database server or knowledge supply. It’s also possible to seek advice from the finest practices information for a reference implementation.
Value administration and chargeback
In a multi-tenant setting, price administration is a vital topic. You have got a number of customers from numerous enterprise models, and also you want to have the ability to exactly chargeback the price of the compute useful resource they’ve used. Firstly of the publish, we launched three fashions of multi-tenancy in Amazon EKS: arduous multi-tenancy, delicate multi-tenancy, and sole multi-tenancy. Laborious multi-tenancy is out of scope as a result of the associated fee monitoring is trivial; all of the assets are devoted to the staff utilizing the cluster, which isn’t the case for sole multi-tenancy and delicate multi-tenancy. Within the subsequent sections, we focus on these two strategies to trace the associated fee for every of mannequin.
Smooth multi-tenancy
In a delicate multi-tenant setting, you possibly can carry out chargeback to your knowledge engineering groups primarily based on the assets they consumed and never the nodes allotted. On this methodology, you employ the namespaces related to the EMR digital cluster to trace how a lot assets have been used for processing jobs. The next diagram illustrates an instance.

Diagram -1 Smooth multi-tenancy
Monitoring assets primarily based on the namespace isn’t a straightforward process as a result of jobs are transient in nature and fluctuate of their period. Nonetheless, there are companion instruments accessible that help you maintain monitor of the assets used, corresponding to Kubecost, CloudZero, Vantage, and plenty of others. For directions on utilizing Kubecost on Amazon EKS, seek advice from this weblog publish on price monitoring for EKS prospects.
Sole multi-tenancy
For sole multi-tenancy, the chargeback is completed on the occasion (node) degree. Every member in your staff makes use of a particular set of nodes which can be devoted to it. These nodes aren’t at all times operating, and are spun up utilizing the Kubernetes auto scaling mechanism. The next diagram illustrates an instance.

Diagram -2 Sole tenancy
With sole multi-tenancy, you employ a price allocation tag, which is an AWS mechanism that means that you can monitor how a lot every useful resource has consumed. Though the strategy of sole multi-tenancy isn’t environment friendly by way of useful resource utilization, it offers a simplified technique for chargebacks. With the associated fee allocation tag, you possibly can chargeback a staff primarily based on all of the assets they used, like Amazon S3, Amazon DynamoDB, and different AWS assets. The chargeback mechanism primarily based on the associated fee allocation tag may be augmented utilizing the lately launched AWS Billing Conductor, which lets you problem payments internally to your staff.
Useful resource administration
On this part, we focus on issues relating to useful resource administration in multi-tenant clusters. We briefly focus on matters like sharing assets graciously, setting guard rails on useful resource consumption, strategies for making certain assets for time delicate and/or vital jobs, assembly fast useful resource scaling necessities and at last price optimization practices with node selectors.
Sharing assets
In a multi-tenant setting, the objective is to share assets like compute and reminiscence for higher useful resource utilization. Nonetheless, this requires cautious capability administration and useful resource allocation to ensure every tenant will get their fair proportion. In Kubernetes, useful resource allocation is managed and enforced through the use of ResourceQuota and LimitRange. ResourceQuota limits assets on the namespace degree, and LimitRange means that you can make it possible for all of the containers are submitted with a useful resource requirement and a restrict. On this part, we reveal how an information engineer or Kubernetes administrator can arrange ResourceQuota as a LimitRange configuration.
The administrator creates one ResourceQuota per namespace that gives constraints for mixture useful resource consumption:
apiVersion: v1
type: ResourceQuota
metadata:
identify: compute-resources
namespace: teamA
spec:
arduous:
requests.cpu: "1000"
requests.reminiscence: 4000Gi
limits.cpu: "2000"
limits.reminiscence: 6000Gi
For LimitRange, the administrator can evaluate the next pattern configuration. We suggest utilizing default and defaultRequest to implement the restrict and request discipline on containers. Lastly, from an information engineer perspective whereas submitting the EMR on EKS jobs, it’s worthwhile to be sure the Spark parameters of useful resource necessities are inside the vary of the outlined LimitRange. For instance, within the following configuration, the request for spark.executor.cores=7 will fail as a result of the max restrict for CPU is 6 per container:
apiVersion: v1
type: LimitRange
metadata:
identify: cpu-min-max
namespace: teamA
spec:
limits:
- max:
cpu: "6"
min:
cpu: "100m"
default:
cpu: "500m"
defaultRequest:
cpu: "100m"
kind: Container
Precedence-based useful resource allocation
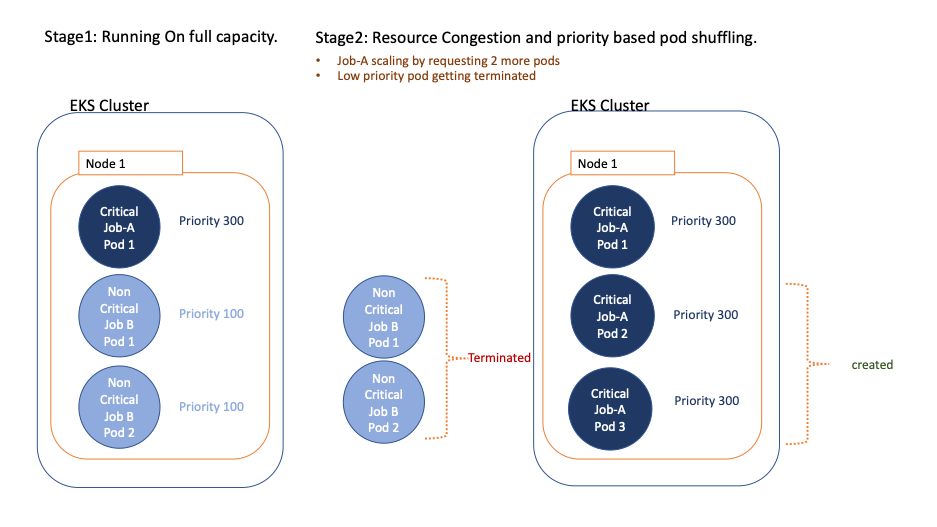
Diagram – 3 Illustrates an instance of useful resource allocation with precedence.
As all of the EMR digital clusters share the identical EKS computing platform with restricted assets, there shall be eventualities by which it’s worthwhile to prioritize jobs in a delicate timeline. On this case, high-priority jobs can make the most of the assets and end the job, whereas low-priority jobs which can be operating will get stopped and any new pods should wait within the queue. EMR on EKS can obtain this with the assistance of pod templates, the place you specify a precedence class for the given job.
When a pod precedence is enabled, the Kubernetes scheduler orders pending pods by their precedence and locations them within the scheduling queue. Consequently, the higher-priority pod could also be scheduled earlier than pods with decrease precedence if its scheduling necessities are met. If this pod can’t be scheduled, the scheduler continues and tries to schedule different lower-priority pods.
The preemptionPolicy discipline on the PriorityClass defaults to PreemptLowerPriority, and the pods of that PriorityClass can preempt lower-priority pods. If preemptionPolicy is ready to By no means, pods of that PriorityClass are non-preempting. In different phrases, they will’t preempt every other pods. When lower-priority pods are preempted, the sufferer pods get a grace interval to complete their work and exit. If the pod doesn’t exit inside that grace interval, that pod is stopped by the Kubernetes scheduler. Due to this fact, there may be normally a time hole between the purpose when the scheduler preempts sufferer pods and the time {that a} higher-priority pod is scheduled. If you wish to reduce this hole, you possibly can set a deletion grace interval of lower-priority pods to zero or a small quantity. You are able to do this by setting the terminationGracePeriodSeconds possibility within the sufferer Pod YAML.
See the next code samples for precedence class:
apiVersion: scheduling.k8s.io/v1
type: PriorityClass
metadata:
identify: high-priority
worth: 100
globalDefault: false
description: " Excessive-priority Pods and for Driver Pods."
apiVersion: scheduling.k8s.io/v1
type: PriorityClass
metadata:
identify: low-priority
worth: 50
globalDefault: false
description: " Low-priority Pods."One of many key issues whereas templatizing the driving force pods, particularly for low-priority jobs, is to keep away from the identical low-priority class for each driver and executor. This can save the driving force pods from getting evicted and lose the progress of all its executors in a useful resource congestion situation. On this low-priority job instance, we now have used a high-priority class for driver pod templates and low-priority lessons just for executor templates. This manner, we are able to guarantee the driving force pods are secure throughout the eviction strategy of low-priority jobs. On this case, solely executors shall be evicted, and the driving force can carry again the evicted executor pods because the useful resource turns into freed. See the next code:
apiVersion: v1
type: Pod
spec:
priorityClassName: "high-priority"
nodeSelector:
eks.amazonaws.com/capacityType: ON_DEMAND
containers:
- identify: spark-kubernetes-driver # This shall be interpreted as Spark driver container
apiVersion: v1
type: Pod
spec:
priorityClassName: "low-priority"
nodeSelector:
eks.amazonaws.com/capacityType: SPOT
containers:
- identify: spark-kubernetes-executors # This shall be interpreted as Spark executor container
Overprovisioning with precedence
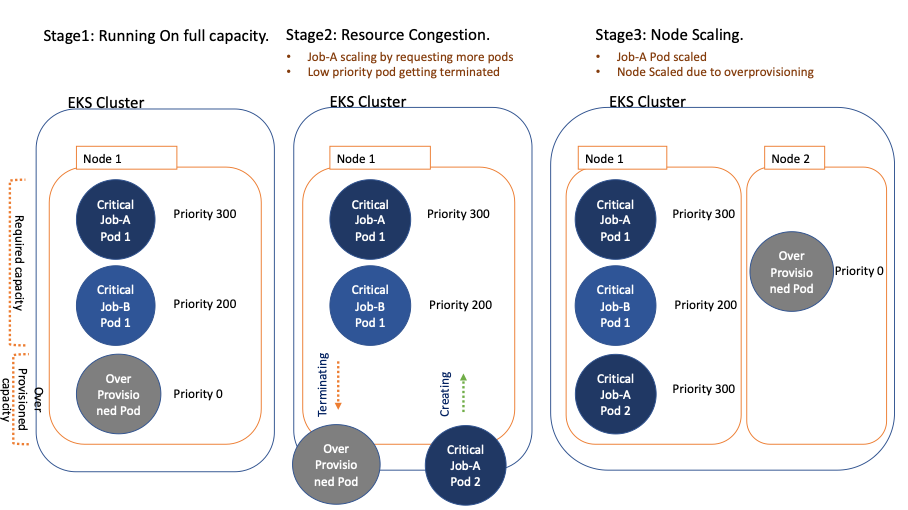
Diagram – 4 Illustrates an instance of overprovisioning with precedence.
As pods wait in a pending state on account of useful resource availability, extra capability may be added to the cluster with Amazon EKS auto scaling. The time it takes to scale the cluster by including new nodes for deployment must be thought-about for time-sensitive jobs. Overprovisioning is an choice to mitigate the auto scaling delay utilizing momentary pods with damaging precedence. These pods occupy house within the cluster. When pods with excessive precedence are unschedulable, the momentary pods are preempted to make the room. This causes the auto scaler to scale out new nodes on account of overprovisioning. Bear in mind that this can be a trade-off as a result of it provides increased price whereas minimizing scheduling latency. For extra details about overprovisioning finest practices, seek advice from Overprovisioning.
Node selectors
EKS clusters can span a number of Availability Zones in a VPC. A Spark software whose driver and executor pods are distributed throughout a number of Availability Zones can incur inter- Availability Zone knowledge switch prices. To attenuate or remove the info switch price, it is best to configure the job to run on a particular Availability Zone and even particular node kind with the assistance of node labels. Amazon EKS locations a set of default labels to determine capability kind (On-Demand or Spot Occasion), Availability Zone, occasion kind, and extra. As well as, we are able to use customized labels to fulfill workload-specific node affinity.
EMR on EKS means that you can select particular nodes in two methods:
- On the job degree. Confer with EKS Node Placement for extra particulars.
- Within the driver and executor degree utilizing pod templates.
When utilizing pod templates, we suggest utilizing on demand cases for driver pods. It’s also possible to think about together with spot cases for executor pods for workloads which can be tolerant of occasional durations when the goal capability just isn’t utterly accessible. Leveraging spot cases help you save price for jobs that aren’t vital and may be terminated. Please refer Outline a NodeSelector in PodTemplates.
Conclusion
On this publish, we offered steerage on the right way to design and deploy EMR on EKS in a multi-tenant EKS setting via completely different lenses: community, safety, price administration, and useful resource administration. For any deployment, we suggest the next:
- Use IRSA with a situation scoped on the EMR on EKS service account
- Use a secret supervisor to retailer credentials and the Secret Retailer CSI Driver to entry them in your Spark software
- Use
ResourceQuotaandLimitRangeto specify the assets that every of your knowledge engineering groups can use and keep away from compute useful resource abuse and hunger - Implement a community coverage to segregate community visitors between pods
Lastly, if you’re contemplating migrating your spark workload to EMR on EKS you possibly can additional find out about design patterns to handle Apache Spark workload in EMR on EKS on this weblog and about migrating your EMR transient cluster to EMR on EKS on this weblog.
In regards to the Authors
 Lotfi Mouhib is a Senior Options Architect working for the Public Sector staff with Amazon Net Companies. He helps public sector prospects throughout EMEA notice their concepts, construct new providers, and innovate for residents. In his spare time, Lotfi enjoys biking and operating.
Lotfi Mouhib is a Senior Options Architect working for the Public Sector staff with Amazon Net Companies. He helps public sector prospects throughout EMEA notice their concepts, construct new providers, and innovate for residents. In his spare time, Lotfi enjoys biking and operating.
 Ajeeb Peter is a Senior Options Architect with Amazon Net Companies primarily based in Charlotte, North Carolina, the place he guides world monetary providers prospects to construct extremely safe, scalable, dependable, and cost-efficient functions on the cloud. He brings over 20 years of expertise expertise on Software program Growth, Structure and Analytics from industries like finance and telecom.
Ajeeb Peter is a Senior Options Architect with Amazon Net Companies primarily based in Charlotte, North Carolina, the place he guides world monetary providers prospects to construct extremely safe, scalable, dependable, and cost-efficient functions on the cloud. He brings over 20 years of expertise expertise on Software program Growth, Structure and Analytics from industries like finance and telecom.





