
SEO, in its most elementary sense, depends upon one factor above all others: Search engine spiders crawling and indexing your website.
However almost each web site goes to have pages that you just don’t need to embrace on this exploration.
For instance, do you really need your privateness coverage or inside search pages displaying up in Google outcomes?
In a best-case state of affairs, these are doing nothing to drive site visitors to your website actively, and in a worst-case, they may very well be diverting site visitors from extra necessary pages.
Fortunately, Google permits site owners to inform search engine bots what pages and content material to crawl and what to disregard. There are a number of methods to do that, the commonest being utilizing a robots.txt file or the meta robots tag.
We’ve a superb and detailed rationalization of the ins and outs of robots.txt, which you need to undoubtedly learn.
However in high-level phrases, it’s a plain textual content file that lives in your web site’s root and follows the Robots Exclusion Protocol (REP).
Robots.txt gives crawlers with directions concerning the website as an entire, whereas meta robots tags embrace instructions for particular pages.
Some meta robots tags you would possibly make use of embrace index, which tells search engines like google and yahoo so as to add the web page to their index; noindex, which tells it to not add a web page to the index or embrace it in search outcomes; observe, which instructs a search engine to observe the hyperlinks on a web page; nofollow, which tells it to not observe hyperlinks, and an entire host of others.
Each robots.txt and meta robots tags are helpful instruments to maintain in your toolbox, however there’s additionally one other strategy to instruct search engine bots to noindex or nofollow: the X-Robots-Tag.
What Is The X-Robots-Tag?
The X-Robots-Tag is one other approach so that you can management how your webpages are crawled and listed by spiders. As a part of the HTTP header response to a URL, it controls indexing for a whole web page, in addition to the particular components on that web page.
And whereas utilizing meta robots tags is pretty easy, the X-Robots-Tag is a little more sophisticated.
However this, after all, raises the query:
When Ought to You Use The X-Robots-Tag?
In keeping with Google, “Any directive that can be utilized in a robots meta tag may also be specified as an X-Robots-Tag.”
Whilst you can set robots.txt-related directives within the headers of an HTTP response with each the meta robots tag and X-Robots Tag, there are specific conditions the place you’ll need to use the X-Robots-Tag – the 2 commonest being when:
- You need to management how your non-HTML recordsdata are being crawled and listed.
- You need to serve directives site-wide as an alternative of on a web page degree.
For instance, if you wish to block a selected picture or video from being crawled – the HTTP response technique makes this simple.
The X-Robots-Tag header can be helpful as a result of it permits you to mix a number of tags inside an HTTP response or use a comma-separated record of directives to specify directives.
Possibly you don’t need a sure web page to be cached and need it to be unavailable after a sure date. You should use a mix of “noarchive” and “unavailable_after” tags to instruct search engine bots to observe these directions.
Primarily, the ability of the X-Robots-Tag is that it’s way more versatile than the meta robots tag.
The benefit of utilizing an X-Robots-Tag with HTTP responses is that it permits you to use common expressions to execute crawl directives on non-HTML, in addition to apply parameters on a bigger, international degree.
That can assist you perceive the distinction between these directives, it’s useful to categorize them by kind. That’s, are they crawler directives or indexer directives?
Right here’s a useful cheat sheet to elucidate:
| Crawler Directives | Indexer Directives |
| Robots.txt – makes use of the consumer agent, enable, disallow, and sitemap directives to specify the place on-site search engine bots are allowed to crawl and never allowed to crawl. | Meta Robots tag – permits you to specify and stop search engines like google and yahoo from displaying specific pages on a website in search outcomes.
Nofollow – permits you to specify hyperlinks that ought to not go on authority or PageRank. X-Robots-tag – permits you to management how specified file sorts are listed. |
The place Do You Put The X-Robots-Tag?
Let’s say you need to block particular file sorts. A perfect method can be so as to add the X-Robots-Tag to an Apache configuration or a .htaccess file.
The X-Robots-Tag might be added to a website’s HTTP responses in an Apache server configuration by way of .htaccess file.
Actual-World Examples And Makes use of Of The X-Robots-Tag
In order that sounds nice in idea, however what does it appear to be in the true world? Let’s have a look.
Let’s say we needed search engines like google and yahoo to not index .pdf file sorts. This configuration on Apache servers would look one thing just like the beneath:
<Information ~ ".pdf$"> Header set X-Robots-Tag "noindex, nofollow" </Information>
In Nginx, it will appear to be the beneath:
location ~* .pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}
Now, let’s have a look at a special state of affairs. Let’s say we need to use the X-Robots-Tag to dam picture recordsdata, resembling .jpg, .gif, .png, and so forth., from being listed. You possibly can do that with an X-Robots-Tag that may appear to be the beneath:
<Information ~ ".(png|jpe?g|gif)$"> Header set X-Robots-Tag "noindex" </Information>
Please notice that understanding how these directives work and the influence they’ve on each other is essential.
For instance, what occurs if each the X-Robots-Tag and a meta robots tag are situated when crawler bots uncover a URL?
If that URL is blocked from robots.txt, then sure indexing and serving directives can’t be found and won’t be adopted.
If directives are to be adopted, then the URLs containing these can’t be disallowed from crawling.
Test For An X-Robots-Tag
There are a number of completely different strategies that can be utilized to test for an X-Robots-Tag on the location.
The simplest strategy to test is to put in a browser extension that can inform you X-Robots-Tag details about the URL.
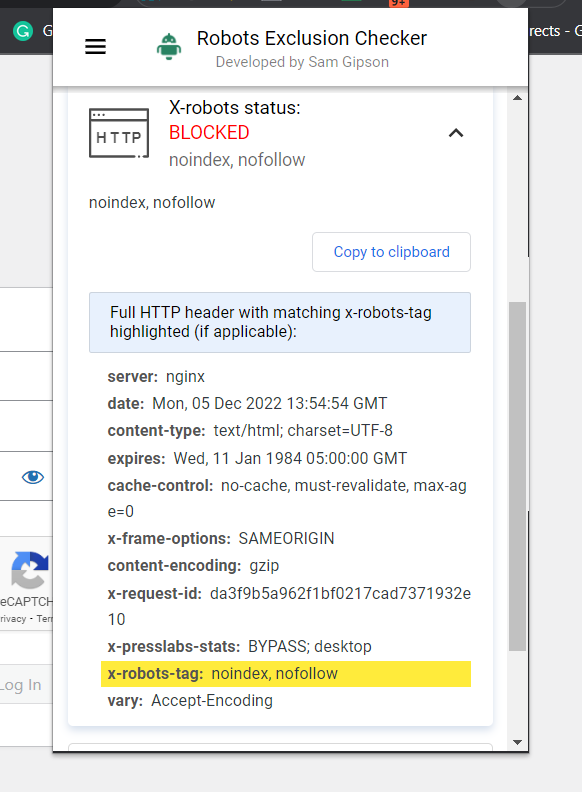 Screenshot of Robots Exclusion Checker, December 2022
Screenshot of Robots Exclusion Checker, December 2022One other plugin you should use to find out whether or not an X-Robots-Tag is getting used, for instance, is the Internet Developer plugin.
By clicking on the plugin in your browser and navigating to “View Response Headers,” you’ll be able to see the varied HTTP headers getting used.

One other technique that can be utilized for scaling with the intention to pinpoint points on web sites with 1,000,000 pages is Screaming Frog.
After operating a website via Screaming Frog, you’ll be able to navigate to the “X-Robots-Tag” column.
This may present you which ones sections of the location are utilizing the tag, together with which particular directives.
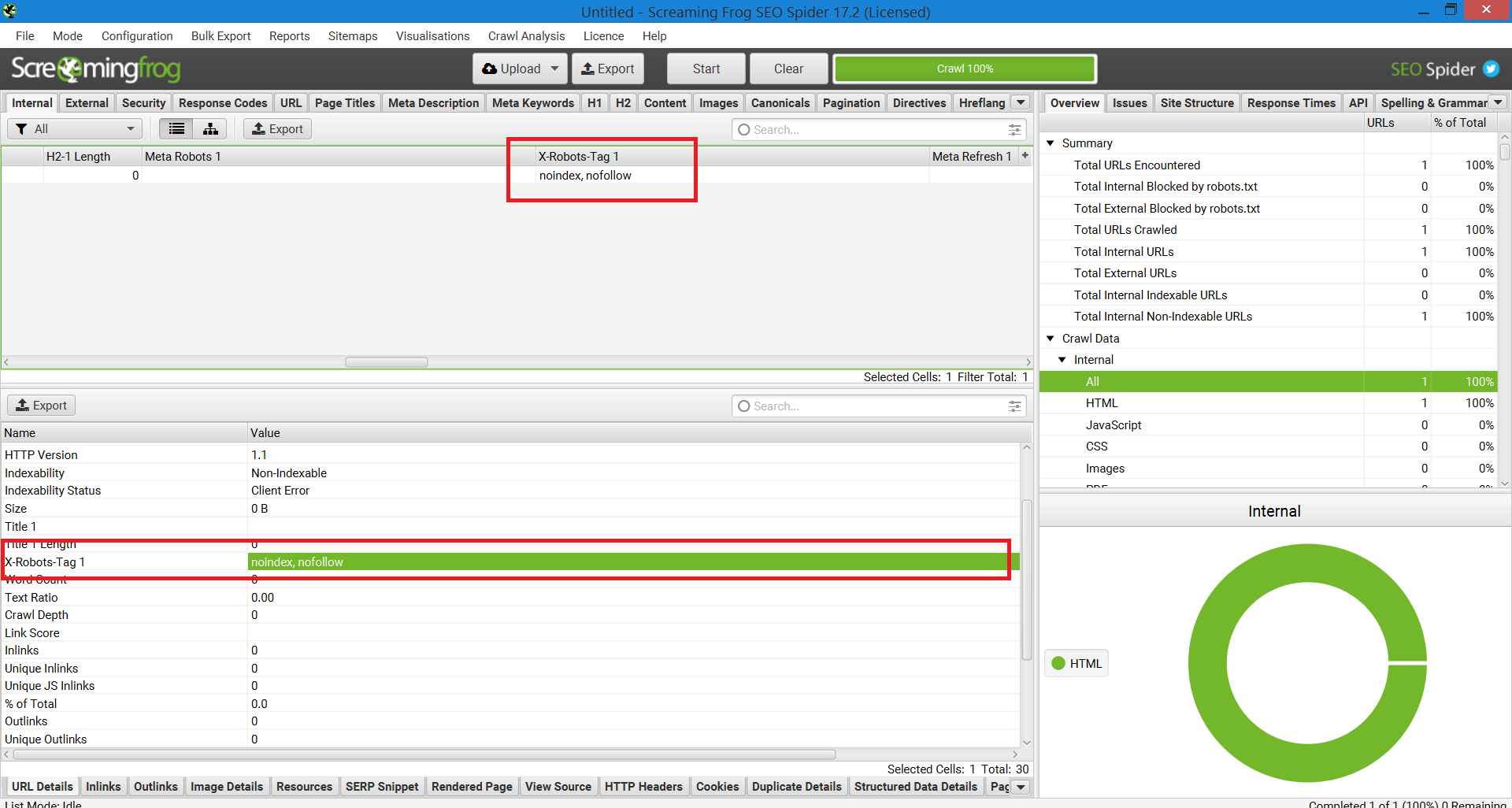 Screenshot of Screaming Frog Report. X-Robotic-Tag, December 2022
Screenshot of Screaming Frog Report. X-Robotic-Tag, December 2022Utilizing X-Robots-Tags On Your Website
Understanding and controlling how search engines like google and yahoo work together along with your web site is the cornerstone of SEO. And the X-Robots-Tag is a robust instrument you should use to do exactly that.
Simply remember: It’s not with out its risks. It is vitally simple to make a mistake and deindex your whole website.
That mentioned, if you happen to’re studying this piece, you’re most likely not an web optimization newbie. As long as you utilize it properly, take your time and test your work, you’ll discover the X-Robots-Tag to be a helpful addition to your arsenal.
Extra Sources:
Featured Picture: Song_about_summer/Shutterstock





