
Many thrilling up to date purposes of laptop science and machine studying (ML) manipulate multidimensional datasets that span a single giant coordinate system, for instance, climate modeling from atmospheric measurements over a spatial grid or medical imaging predictions from multi-channel picture depth values in a 2nd or 3d scan. In these settings, even a single dataset might require terabytes or petabytes of information storage. Such datasets are additionally difficult to work with as customers might learn and write knowledge at irregular intervals and ranging scales, and are sometimes occupied with performing analyses utilizing quite a few machines working in parallel.
Immediately we’re introducing TensorStore, an open-source C++ and Python software program library designed for storage and manipulation of n-dimensional knowledge that:
- Offers a uniform API for studying and writing a number of array codecs, together with zarr and N5.
- Natively helps a number of storage programs, together with Google Cloud Storage, native and community filesystems, HTTP servers, and in-memory storage.
- Helps learn/writeback caching and transactions, with robust atomicity, isolation, consistency, and sturdiness (ACID) ensures.
- Helps secure, environment friendly entry from a number of processes and machines through optimistic concurrency.
- Gives an asynchronous API to allow high-throughput entry even to high-latency distant storage.
- Offers superior, totally composable indexing operations and digital views.
TensorStore has already been used to resolve key engineering challenges in scientific computing (e.g., administration and processing of enormous datasets in neuroscience, corresponding to peta-scale 3d electron microscopy knowledge and “4d” movies of neuronal exercise). TensorStore has additionally been used within the creation of large-scale machine studying fashions corresponding to PaLM by addressing the issue of managing mannequin parameters (checkpoints) throughout distributed coaching.
Acquainted API for Information Entry and Manipulation
TensorStore offers a easy Python API for loading and manipulating giant array knowledge. Within the following instance, we create a TensorStore object that represents a 56 trillion voxel 3d picture of a fly mind and entry a small 100×100 patch of the information as a NumPy array:
>>> import tensorstore as ts
>>> import numpy as np
# Create a TensorStore object to work with fly mind knowledge.
>>> dataset = ts.open({
... 'driver':
... 'neuroglancer_precomputed',
... 'kvstore':
... 'gs://neuroglancer-janelia-flyem-hemibrain/v1.1/segmentation/',
... }).outcome()
# Create a 3D view (take away singleton 'channel' dimension):
>>> dataset_3d = dataset[ts.d['channel'][0]]
>>> dataset_3d.area
{ "x": [0, 34432), "y": [0, 39552), "z": [0, 41408) }
# Convert a 100x100x1 slice of the data to a numpy ndarray
>>> slice = np.array(dataset_3d[15000:15100, 15000:15100, 20000])
Crucially, no precise knowledge is accessed or saved in reminiscence till the precise 100×100 slice is requested; therefore arbitrarily giant underlying datasets could be loaded and manipulated with out having to retailer your entire dataset in reminiscence, utilizing indexing and manipulation syntax largely similar to straightforward NumPy operations. TensorStore additionally offers in depth help for superior indexing options, together with transforms, alignment, broadcasting, and digital views (knowledge kind conversion, downsampling, lazily on-the-fly generated arrays).
The next instance demonstrates how TensorStore can be utilized to create a zarr array, and the way its asynchronous API allows larger throughput:
>>> import tensorstore as ts
>>> import numpy as np
>>> # Create a zarr array on the native filesystem
>>> dataset = ts.open({
... 'driver': 'zarr',
... 'kvstore': 'file:///tmp/my_dataset/',
... },
... dtype=ts.uint32,
... chunk_layout=ts.ChunkLayout(chunk_shape=[256, 256, 1]),
... create=True,
... form=[5000, 6000, 7000]).outcome()
>>> # Create two numpy arrays with instance knowledge to write down.
>>> a = np.arange(100*200*300, dtype=np.uint32).reshape((100, 200, 300))
>>> b = np.arange(200*300*400, dtype=np.uint32).reshape((200, 300, 400))
>>> # Provoke two asynchronous writes, to be carried out concurrently.
>>> future_a = dataset[1000:1100, 2000:2200, 3000:3300].write(a)
>>> future_b = dataset[3000:3200, 4000:4300, 5000:5400].write(b)
>>> # Watch for the asynchronous writes to finish
>>> future_a.outcome()
>>> future_b.outcome()
Protected and Performant Scaling
Processing and analyzing giant numerical datasets requires vital computational sources. That is usually achieved by means of parallelization throughout quite a few CPU or accelerator cores unfold throughout many machines. Subsequently a elementary aim of TensorStore has been to allow parallel processing of particular person datasets that’s each secure (i.e., avoids corruption or inconsistencies arising from parallel entry patterns) and excessive efficiency (i.e., studying and writing to TensorStore isn’t a bottleneck throughout computation). In actual fact, in a take a look at inside Google’s datacenters, we discovered practically linear scaling of learn and write efficiency because the variety of CPUs was elevated:
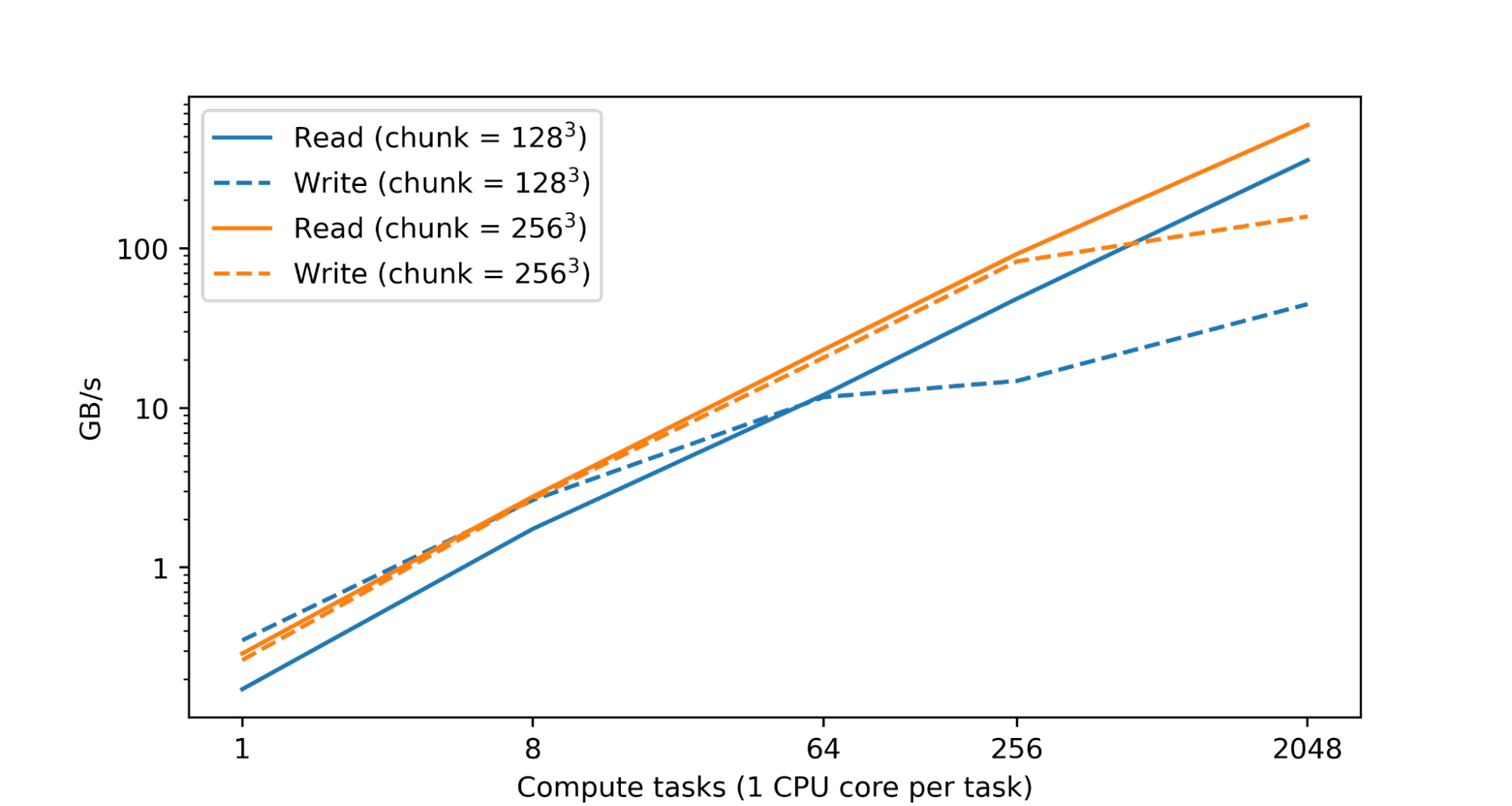 |
| Learn and write efficiency for a TensorStore dataset in zarr format residing on Google Cloud Storage (GCS) accessed concurrently utilizing a variable variety of single-core compute duties in Google knowledge facilities. Each learn and write efficiency scales practically linearly with the variety of compute duties. |
Efficiency is achieved by implementing core operations in C++, in depth use of multithreading for operations corresponding to encoding/decoding and community I/O, and partitioning giant datasets into a lot smaller models by means of chunking to allow effectively studying and writing subsets of your entire dataset. TensorStore additionally offers configurable in-memory caching (which reduces slower storage system interactions for steadily accessed knowledge) and an asynchronous API that permits a learn or write operation to proceed within the background whereas a program completes different work.
Security of parallel operations when many machines are accessing the identical dataset is achieved by means of using optimistic concurrency, which maintains compatibility with numerous underlying storage layers (together with Cloud storage platforms, corresponding to GCS, in addition to native filesystems) with out considerably impacting efficiency. TensorStore additionally offers robust ACID ensures for all particular person operations executing inside a single runtime.
To make distributed computing with TensorStore appropriate with many present knowledge processing workflows, we’ve additionally built-in TensorStore with parallel computing libraries corresponding to Apache Beam (instance code) and Dask (instance code).
Use Case: Language Fashions
An thrilling latest improvement in ML is the emergence of extra superior language fashions corresponding to PaLM. These neural networks include a whole lot of billions of parameters and exhibit some stunning capabilities in pure language understanding and technology. These fashions additionally push the boundaries of computational infrastructure; particularly, coaching a language mannequin corresponding to PaLM requires 1000’s of TPUs working in parallel.
One problem that arises throughout this coaching course of is effectively studying and writing the mannequin parameters. Coaching is distributed throughout many separate machines, however parameters have to be often saved to a single object (“checkpoint”) on a everlasting storage system with out slowing down the general coaching course of. Particular person coaching jobs should additionally have the ability to learn simply the precise set of parameters they’re involved with with the intention to keep away from the overhead that will be required to load your entire set of mannequin parameters (which might be a whole lot of gigabytes).
TensorStore has already been used to deal with these challenges. It has been utilized to handle checkpoints related to large-scale (“multipod”) fashions skilled with JAX (code instance) and has been built-in with frameworks corresponding to T5X (code instance) and Pathways. Mannequin parallelism is used to partition the total set of parameters, which might occupy greater than a terabyte of reminiscence, over a whole lot of TPUs. Checkpoints are saved in zarr format utilizing TensorStore, with a piece construction chosen to permit the partition for every TPU to be learn and written independently in parallel.
|
| When saving a checkpoint, every mannequin parameter is written utilizing TensorStore in zarr format utilizing a piece grid that additional subdivides the grid used to partition the parameter over TPUs. The host machines write in parallel the zarr chunks for every of the partitions assigned to TPUs connected to that host. Utilizing TensorStore’s asynchronous API, coaching proceeds even whereas the information remains to be being written to persistent storage. When resuming from a checkpoint, every host reads solely the chunks that make up the partitions assigned to that host. |
Use Case: 3D Mind Mapping
The sphere of synapse-resolution connectomics goals to map the wiring of animal and human brains on the detailed stage of particular person synaptic connections. This requires imaging the mind at extraordinarily excessive decision (nanometers) over fields of view of as much as millimeters or extra, which yields datasets that may span petabytes in dimension. Sooner or later these datasets might prolong to exabytes as scientists ponder mapping whole mouse or primate brains. Nonetheless, even present datasets pose vital challenges associated to storage, manipulation, and processing; particularly, even a single mind pattern might require thousands and thousands of gigabytes with a coordinate system (pixel house) of a whole lot of 1000’s pixels in every dimension.
We’ve got used TensorStore to resolve computational challenges related to large-scale connectomic datasets. Particularly, TensorStore has managed a number of the largest and most generally accessed connectomic datasets, with Google Cloud Storage because the underlying object storage system. For instance, it has been utilized to the human cortex “h01” dataset, which is a 3d nanometer-resolution picture of human mind tissue. The uncooked imaging knowledge is 1.4 petabytes (roughly 500,000 * 350,000 * 5,000 pixels giant, and is additional related to further content material corresponding to 3d segmentations and annotations that reside in the identical coordinate system. The uncooked knowledge is subdivided into particular person chunks 128x128x16 pixels giant and saved within the “Neuroglancer precomputed” format, which is optimized for web-based interactive viewing and could be simply manipulated from TensorStore.
Getting Began
To get began utilizing the TensorStore Python API, you’ll be able to set up the tensorstore PyPI package deal utilizing:
pip set up tensorstore
Consult with the tutorials and API documentation for utilization particulars. For different set up choices and for utilizing the C++ API, check with set up directions.
Acknowledgements
Because of Tim Blakely, Viren Jain, Yash Katariya, Jan-Matthis Luckmann, Michał Januszewski, Peter Li, Adam Roberts, Mind Williams, and Hector Yee from Google Analysis, and Davis Bennet, Stuart Berg, Eric Perlman, Stephen Plaza, and Juan Nunez-Iglesias from the broader scientific neighborhood for useful suggestions on the design, early testing and debugging.




