
Current advances in ease of use and scalability have made streaming knowledge simpler to generate and use for real-time decision-making. Coupled with market forces which have compelled companies to react extra rapidly to business modifications, an increasing number of organizations immediately are turning to streaming knowledge to gas innovation and agility.
Amazon Managed Streaming for Apache Kafka (MSK) is a completely managed service that makes it straightforward to construct and run functions that use Apache Kafka, an open-source distributed occasion streaming platform designed for high-performance knowledge pipelines, streaming analytics, knowledge integration, and mission-critical functions. With Amazon MSK, you’ll be able to seize real-time knowledge from a variety of sources comparable to database change occasions or net utility consumer clickstreams. Since Kafka is extremely optimized for writing and studying contemporary knowledge, it’s an awesome match for operational reporting. Nevertheless, gaining perception from this knowledge usually requires a specialised stream processing layer to put in writing streaming information to a storage medium like Amazon S3, the place it may be accessed by analysts, knowledge scientists, and knowledge engineers for historic evaluation and visualization utilizing instruments like Amazon QuickSight.
While you need to analyze knowledge the place it lives and with out growing separate pipelines and jobs, a well-liked alternative is Amazon Athena. With Athena, you should use your current SQL information to extract insights from a variety of knowledge sources with out studying a brand new language, growing scripts to extract (and duplicate) knowledge, or managing infrastructure. Athena helps over 25 connectors to well-liked knowledge sources together with Amazon DynamoDB and Amazon Redshift which give knowledge analysts, knowledge engineers, and knowledge scientists the flexibleness to run SQL queries on knowledge saved in databases operating on-premises or within the cloud alongside knowledge saved in Amazon S3. With Athena, there’s no knowledge motion and also you pay just for the queries you run.
What’s new
Beginning immediately, now you can use Athena to question streaming knowledge in MSK and self-managed Apache Kafka. This allows you to run analytical queries on real-time knowledge held in Kafka subjects and be part of that knowledge with different Kafka subjects in addition to different knowledge in your Amazon S3 knowledge lake – all with out the necessity for separate processes to first retailer the info on Amazon S3.
Answer overview
On this submit, we present you learn how to get began with real-time SQL analytics utilizing Athena and its connector for MSK. The method entails:
- Registering the schema of your streaming knowledge with AWS Glue Schema Registry. Schema Registry is a function of AWS Glue that lets you validate and reliably evolve streaming knowledge in opposition to JSON schemas. It might probably additionally serialize knowledge right into a compressed format, which helps you save on knowledge switch and storage prices.
- Creating a brand new occasion of the Amazon Athena MSK Connector. Athena connectors are pre-built functions that run as serverless AWS Lambda functions, so there’s no want for standalone knowledge export processes.
- Utilizing the Athena console to run interactive SQL queries in your Kafka subjects.
Get began with Athena’s connector for Amazon MSK
On this part, we’ll cowl the steps essential to arrange your MSK cluster to work with Athena to run SQL queries in your Kafka subjects.
Stipulations
This submit assumes you have got a serverless or provisioned MSK cluster set as much as obtain streaming messages from a producing utility. For data, see Organising Amazon MSK and Getting began utilizing Amazon MSK within the Amazon Managed Streaming for Apache Kafka Developer Information.
You’ll additionally have to set up a VPC and a safety group earlier than you utilize the Athena connector for MSK. For extra data, see Making a VPC for a knowledge supply connector. Be aware that with MSK Serverless, VPCs and safety teams are created robotically, so you will get began rapidly.
Outline the schema of your Kafka subjects with AWS Glue Schema Registry
To run SQL queries in your Kafka subjects, you’ll first have to outline the schema of your subjects as Athena makes use of this metadata for question planning. AWS Glue makes it straightforward to do that with its Schema Registry function for streaming knowledge sources.
Schema Registry lets you centrally uncover, management, and evolve streaming knowledge schemas to be used in analytics functions comparable to Athena. With AWS Glue Schema Registry, you’ll be able to handle and implement schemas in your knowledge streaming functions utilizing handy integrations with Apache Kafka. To study extra, see AWS Glue Schema Registry and Getting began with Schema Registry.
If configured to take action, the producer of knowledge can auto-register its schema and modifications to it with AWS Glue. That is particularly helpful in use instances the place the contents of the info is prone to change over time. Nevertheless, you can too specify the schema manually and can resemble the next JSON construction.
When organising your Schema Registry, remember to give it an easy-to-remember identify, comparable to customer_schema, since you’ll reference it inside SQL queries as you’ll see afterward. For added data on schema arrange, see Schema examples for the AWS Glue Schema Registry.
Configure the Athena connector for MSK
Together with your schema registered with Glue, the following step is to arrange the Athena connector for MSK. We suggest utilizing the Athena console for this step. For extra background on the steps concerned, see Deploying a connector and connecting to a knowledge supply.
In Athena, federated knowledge supply connectors are functions that run on AWS Lambda and deal with communication between your goal knowledge supply and Athena. When a question runs on a federated supply, Athena calls the Lambda operate and duties it with operating the components of your question which might be particular to that supply. To study extra concerning the question execution workflow, see Utilizing Amazon Athena Federated Question within the Amazon Athena Consumer Information.
Begin by accessing the Athena console and deciding on Knowledge sources on the left navigation, then select Create knowledge supply:

Subsequent, seek for and choose Amazon MSK from the out there connectors and choose Subsequent.

In Knowledge supply particulars, give your connector a reputation, like msk, that’s straightforward to recollect and reference in your future SQL queries. Below Connection particulars part, choose Create Lambda operate. This may deliver you to the AWS Lambda console the place you’ll present further configuration properties.
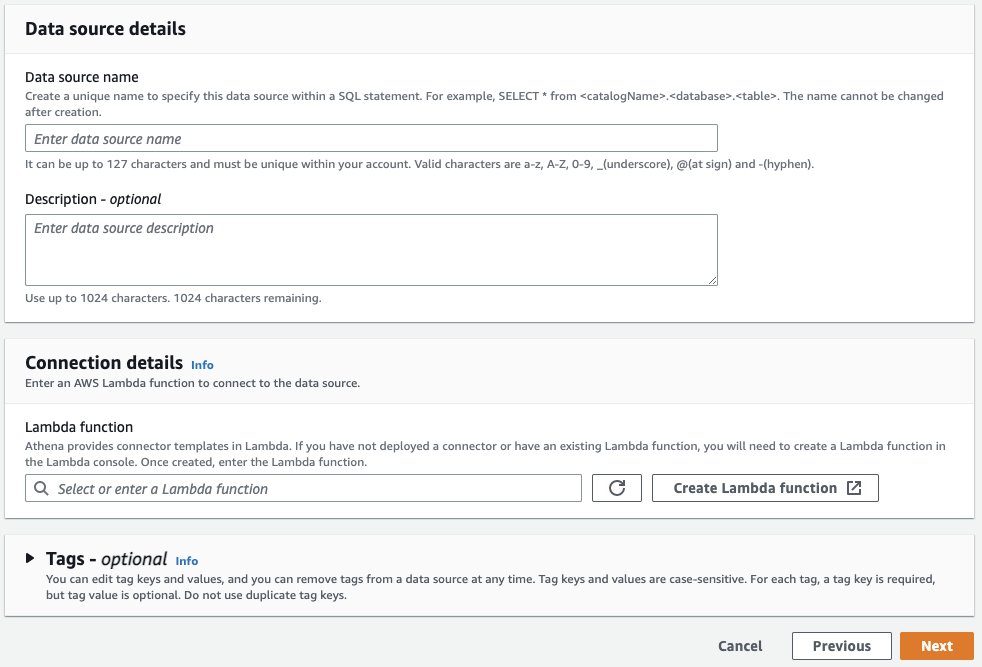
Within the Lambda utility configuration display (not proven), you’ll present the Software settings on your connector. To do that, you’ll want just a few properties out of your MSK cluster and schema registered in Glue.
On one other browser tab, use the MSK console to navigate to your MSK cluster after which choose the Properties tab. Right here you’ll see the VPC subnets and safety group IDs out of your MSK cluster which you’ll present within the SubnetIds and SecurityGroupIds fields within the Athena connector’s Software settings type. You’ll find the worth for KafkaEndpoint by clicking View consumer data.
Within the AWS Glue console, navigate to your Schema Registry to seek out the GlueRegistryArn for the schema you want to use with this connector.
After offering these and the opposite required values, click on Deploy.
Return to the Athena console and enter the identify of the Lambda operate you simply created within the Connection particulars field, then click on Create knowledge supply.
Run queries on streaming knowledge utilizing Athena
Together with your MSK knowledge connector arrange, now you can run SQL queries on the info. Let’s discover just a few use instances in additional element.
Use case: interactive evaluation
If you wish to run queries that mixture, group, or filter your MSK knowledge, you’ll be able to run interactive queries utilizing Athena. These queries will run in opposition to the present state of your Kafka subjects on the time the question was submitted.
Earlier than operating any queries, it could be useful to validate the schema and knowledge varieties out there inside your Kafka subjects. To do that, run the DESCRIBE command in your Kafka matter, which seems in Athena as a desk, as proven under. On this question, the orders desk corresponds to the subject you specified within the Schema Registry.
Now that you understand the contents of your matter, you’ll be able to start to develop analytical queries. A pattern question for a hypothetical Kafka matter containing e-commerce order knowledge is proven under:
As a result of the orders desk (and underlying Kafka matter) can include an unbounded stream of knowledge, the question above is prone to return a unique worth for SUM(order_total) with every execution of the question.
If in case you have knowledge in a single matter that it is advisable to be part of with one other matter, you are able to do that too:
Use case: ingesting streaming knowledge to a desk on Amazon S3
Federated queries run in opposition to the underlying knowledge supply which ensures interactive queries, like those above, are evaluated in opposition to the present state of your knowledge. One consideration is that repeatedly operating federated queries can put further load on the underlying supply. In case you plan to carry out a number of queries on the identical supply knowledge, you should use Athena’s CREATE TABLE AS SELECT, also referred to as CTAS, to retailer the outcomes of a SELECT question in a desk on Amazon S3. You possibly can then run queries in your newly created desk with out going again to the underlying supply every time.
In case you plan to do further downstream evaluation on this knowledge, for instance inside dashboards on Amazon QuickSight, you’ll be able to improve the answer above by periodically including new knowledge to your desk. To study extra, see Utilizing CTAS and INSERT INTO for ETL and knowledge evaluation. One other advantage of this strategy is that you would be able to safe these tables with row-, column-, and table-level knowledge governance insurance policies powered by AWS Lake Formation to make sure solely approved customers can entry your desk.
What else are you able to do?
With Athena, you should use your current SQL information to run federated queries that generate insights from a variety of knowledge sources with out studying a brand new language, growing scripts to extract (and duplicate) knowledge, or managing infrastructure. Athena supplies further integrations with different AWS companies and well-liked analytics instruments and SQL IDEs that let you do far more together with your knowledge. For instance, you’ll be able to:
- Visualize the info in enterprise intelligence functions like Amazon QuickSight
- Design event-driven knowledge processing workflows with Athena’s integration with AWS Step Capabilities
- Unify a number of knowledge sources to provide wealthy enter options for machine studying in Amazon SageMaker
Conclusion
On this submit, we discovered concerning the newly launched Athena connector for Amazon MSK. With it, you’ll be able to run interactive queries on knowledge held in Kafka subjects operating in MSK or self-managed Apache Kafka. This helps you deliver real-time insights to dashboards or allow point-in-time evaluation of streaming knowledge to reply time-sensitive enterprise questions. We additionally lined learn how to periodically ingest new streaming knowledge into Amazon S3 with out the necessity for a separate sink course of. This simplifies recurring evaluation of your knowledge with out incurring round-trip queries to your underlying Kafka clusters and makes it doable to safe the info with entry guidelines powered by Lake Formation.
We encourage you to judge Athena and federated queries in your subsequent analytics challenge. For assist getting began, we suggest the next sources:
Concerning the authors
 Scott Rigney is a Senior Technical Product Supervisor with Amazon Net Companies (AWS) and works with the Amazon Athena staff based mostly out of Arlington, Virginia. He’s enthusiastic about constructing analytics merchandise that allow enterprises to make data-driven choices.
Scott Rigney is a Senior Technical Product Supervisor with Amazon Net Companies (AWS) and works with the Amazon Athena staff based mostly out of Arlington, Virginia. He’s enthusiastic about constructing analytics merchandise that allow enterprises to make data-driven choices.
 Kiran Matty is a Principal Product Supervisor with Amazon Net Companies (AWS) and works with the Amazon Managed Streaming for Apache Kafka (Amazon MSK) staff based mostly out of Palo Alto, California. He’s enthusiastic about constructing performant streaming and analytical companies that assist enterprises notice their important use instances.
Kiran Matty is a Principal Product Supervisor with Amazon Net Companies (AWS) and works with the Amazon Managed Streaming for Apache Kafka (Amazon MSK) staff based mostly out of Palo Alto, California. He’s enthusiastic about constructing performant streaming and analytical companies that assist enterprises notice their important use instances.





