
Amazon Redshift is a totally managed, petabyte-scale information warehouse service within the cloud. Amazon Redshift allows you to run advanced SQL analytics at scale and efficiency on terabytes to petabytes of structured and unstructured information, and make the insights broadly out there by means of common enterprise intelligence (BI) and analytics instruments.
It’s frequent to ingest a number of information sources into Amazon Redshift to carry out analytics. Usually, every information supply could have its personal processes of making and sustaining information, which may result in information high quality challenges inside and throughout sources.
One problem you could face when performing analytics is the presence of imperfect duplicate information inside the supply information. Answering questions so simple as “What number of distinctive prospects do we now have?” may be very difficult when the information you might have out there is like the next desk.
| Identify | Handle | Date of Beginning |
| Cody Johnson | 8 Jeffery Brace, St. Lisatown | 1/3/1956 |
| Cody Jonson | 8 Jeffery Brace, St. Lisatown | 1/3/1956 |
Though people can establish that Cody Johnson and Cody Jonson are more than likely the identical particular person, it may be troublesome to differentiate this utilizing analytics instruments. This identification of duplicate information additionally turns into practically unattainable when engaged on massive datasets throughout a number of sources.
This publish presents one potential strategy to addressing this problem in an Amazon Redshift information warehouse. We import an open-source fuzzy matching Python library to Amazon Redshift, create a easy fuzzy matching user-defined operate (UDF), after which create a process that weights a number of columns in a desk to search out matches primarily based on consumer enter. This strategy permits you to use the created process to roughly establish your distinctive prospects, bettering the accuracy of your analytics.
This strategy doesn’t remedy for information high quality points in supply methods, and doesn’t take away the necessity to have a wholistic information high quality technique. For addressing information high quality challenges in Amazon Easy Storage Service (Amazon S3) information lakes and information pipelines, AWS has introduced AWS Glue Information High quality (preview). It’s also possible to use AWS Glue DataBrew, a visible information preparation instrument that makes it simple for information analysts and information scientists to scrub and normalize information to arrange it for analytics.
Conditions
To finish the steps on this publish, you want the next:
The next AWS CloudFormation stack will deploy a brand new Redshift Serverless endpoint and an S3 bucket to be used on this publish.
![]()
All SQL instructions proven on this publish can be found within the following pocket book, which may be imported into the Amazon Redshift Question Editor V2.
Overview of the dataset getting used
The dataset we use is mimicking a supply that holds buyer data. This supply has a guide strategy of inserting and updating buyer information, and this has led to a number of situations of non-unique prospects being represented with duplicate information.
The next examples present a number of the information high quality points within the dataset getting used.
On this first instance, all three prospects are the identical particular person however have slight variations within the spelling of their names.
| id | identify | age | address_line1 | metropolis | postcode | state |
| 1 | Cody Johnson | 80 | 8 Jeffrey Brace | St. Lisatown | 2636 | South Australia |
| 101 | Cody Jonson | 80 | 8 Jeffrey Brace | St. Lisatown | 2636 | South Australia |
| 121 | Kody Johnson | 80 | 8 Jeffrey Brace | St. Lisatown | 2636 | South Australia |
On this subsequent instance, the 2 prospects are the identical particular person with barely totally different addresses.
| id | identify | age | address_line1 | metropolis | postcode | state |
| 7 | Angela Watson | 59 | 3/752 Bernard Observe | Janiceberg | 2995 | Australian Capital Territory |
| 107 | Angela Watson | 59 | 752 Bernard Observe | Janiceberg | 2995 | Australian Capital Territory |
On this instance, the 2 prospects are totally different individuals with the identical handle. This simulates a number of totally different prospects residing on the similar handle who ought to nonetheless be acknowledged as totally different individuals.
| id | identify | age | address_line1 | metropolis | postcode | state |
| 6 | Michael Hunt | 69 | 8 Santana Relaxation | St. Jessicamouth | 2964 | Queensland |
| 106 | Sarah Hunt | 69 | 8 Santana Relaxation | St. Jessicamouth | 2964 | Queensland |
Load the dataset
First, create a brand new desk in your Redshift Serverless endpoint and replica the take a look at information into it by doing the next:
- Open the Question Editor V2 and log in utilizing the admin consumer identify and particulars outlined when the endpoint was created.
- Run the next CREATE TABLE assertion:

- Run the next COPY command to repeat information into the newly created desk:
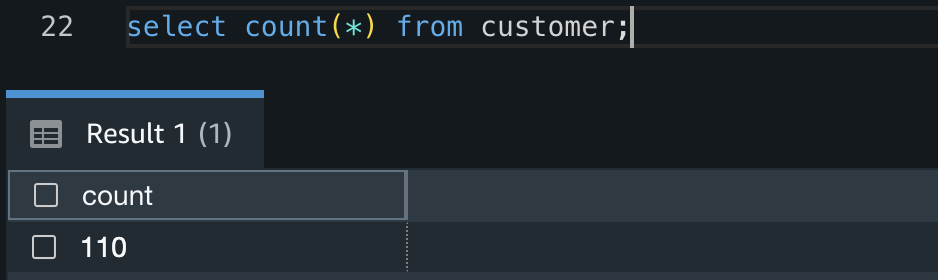
- Verify the COPY succeeded and there are 110 information within the desk by working the next question:
Fuzzy matching
Fuzzy string matching, extra formally generally known as approximate string matching, is the strategy of discovering strings that match a sample roughly quite than precisely. Generally (and on this resolution), the Levenshtein distance is used to measure the space between two strings, and due to this fact their similarity. The smaller the Levenshtein distance between two strings, the extra comparable they’re.
On this resolution, we exploit this property of the Levenshtein distance to estimate if two prospects are the identical particular person primarily based on a number of attributes of the shopper, and it may be expanded to go well with many various use circumstances.
This resolution makes use of TheFuzz, an open-source Python library that implements the Levenshtein distance in a number of alternative ways. We use the partial_ratio operate to check two strings and supply a consequence between 1–100. If one of many strings matches completely with a portion of the opposite, the partial_ratio operate will return 100.
Weighted fuzzy matching
By including a scaling issue to every of our column fuzzy matches, we will create a weighted fuzzy match for a document. That is particularly helpful in two situations:
- We now have extra confidence in some columns of our information than others, and due to this fact wish to prioritize their similarity outcomes.
- One column is for much longer than the others. A single character distinction in an extended string could have a lot much less impression on the Levenshtein distance than a single character distinction in a brief string. Due to this fact, we wish to prioritize lengthy string matches over quick string matches.
The answer on this publish applies weighted fuzzy matching primarily based on consumer enter outlined in one other desk.
Create a desk for weight data
This reference desk holds two columns; the desk identify and the column mapping with weights. The column mapping is held in a SUPER datatype, which permits JSON semistructured information to be inserted and queried straight in Amazon Redshift. For examples on the way to question semistructured information in Amazon Redshift, check with Querying semistructured information.
On this instance, we apply the biggest weight to the column address_line1 (0.5) and the smallest weight to the metropolis and postcode columns (0.1).
Utilizing the Question Editor V2, create a brand new desk in your Redshift Serverless endpoint and insert a document by doing the next:
- Run the next CREATE TABLE assertion:
- Run the next INSERT assertion:
- Verify the mapping information has inserted into the desk accurately by working the next question:

- To examine all weights for the
buyerdesk add as much as 1 (100%), run the next question: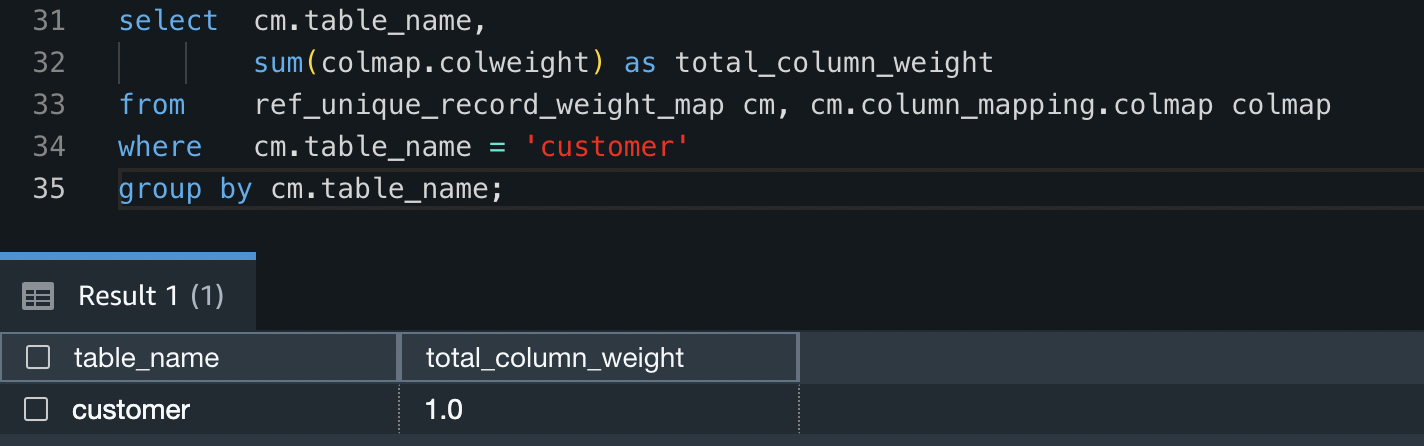
Person-defined capabilities
With Amazon Redshift, you possibly can create customized scalar user-defined capabilities (UDFs) utilizing a Python program. A Python UDF incorporates a Python program that runs when the operate is named and returns a single worth. Along with utilizing the usual Python performance, you possibly can import your personal customized Python modules, such because the module described earlier (TheFuzz).
On this resolution, we create a Python UDF to take two enter values and evaluate their similarity.
Import exterior Python libraries to Amazon Redshift
Run the next code snippet to import the TheFuzz module into Amazon Redshift as a brand new library. This makes the library out there inside Python UDFs within the Redshift Serverless endpoint. Ensure that to offer the identify of the S3 bucket you created earlier.
Create a Python user-defined operate
Run the next code snippet to create a brand new Python UDF referred to as unique_record. This UDF will do the next:
- Take two enter values that may be of any information sort so long as they’re the identical information sort (similar to two integers or two varchars).
- Import the newly created
thefuzzPython library. - Return an integer worth evaluating the partial ratio between the 2 enter values.
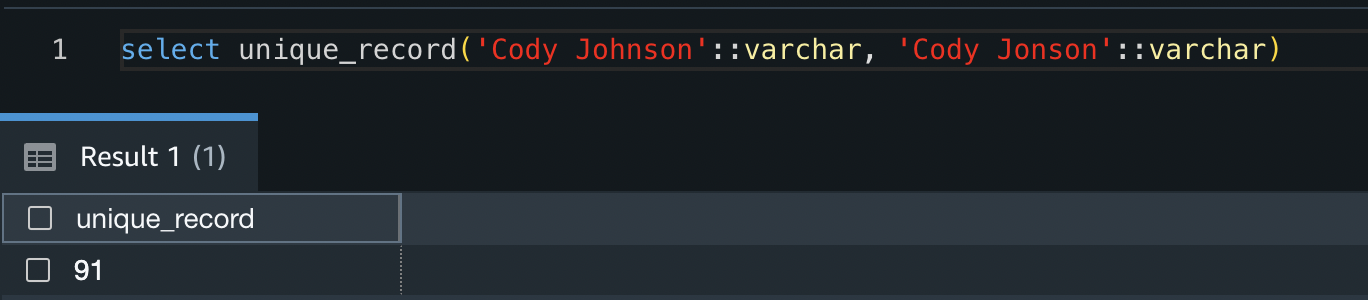
You may take a look at the operate by working the next code snippet:
The consequence exhibits that these two strings are have a similarity worth of 91%.
Now that the Python UDF has been created, you possibly can take a look at the response of various enter values.
Alternatively, you possibly can comply with the amazon-redshift-udfs GitHub repo to put in the f_fuzzy_string_match Python UDF.
Saved procedures
Saved procedures are generally used to encapsulate logic for information transformation, information validation, and business-specific logic. By combining a number of SQL steps right into a saved process, you possibly can scale back spherical journeys between your purposes and the database.
On this resolution, we create a saved process that applies weighting to a number of columns. As a result of this logic is frequent and repeatable whatever the supply desk or information, it permits us to create the saved process as soon as and use it for a number of functions.
Create a saved process
Run the next code snippet to create a brand new Amazon Redshift saved process referred to as find_unique_id. This process will do the next:
- Take one enter worth. This worth is the desk you wish to create a golden document for (in our case, the
buyerdesk). - Declare a set of variables for use all through the process.
- Examine to see if weight information is within the staging desk created in earlier steps.
- Construct a question string for evaluating every column and making use of weights utilizing the load information inserted in earlier steps.
- For every document within the enter desk that doesn’t have a singular document ID (URID) but, it is going to do the next:
- Create a brief desk to stage outcomes. This momentary desk could have all potential URIDs from the enter desk.
- Allocate a similarity worth to every URID. This worth specifies how comparable this URID is to the document in query, weighted with the inputs outlined.
- Select the closest matched URID, however provided that there’s a >90% match.
- If there isn’t a URID match, create a brand new URID.
- Replace the supply desk with the brand new URID and transfer to the following document.
This process will solely ever search for new URIDs for information that don’t have already got one allotted. Due to this fact, rerunning the URID process a number of instances could have no impression on the outcomes.
Now that the saved process has been created, create the distinctive document IDs for the buyer desk by working the next within the Question Editor V2. This may replace the urid column of the buyer desk.
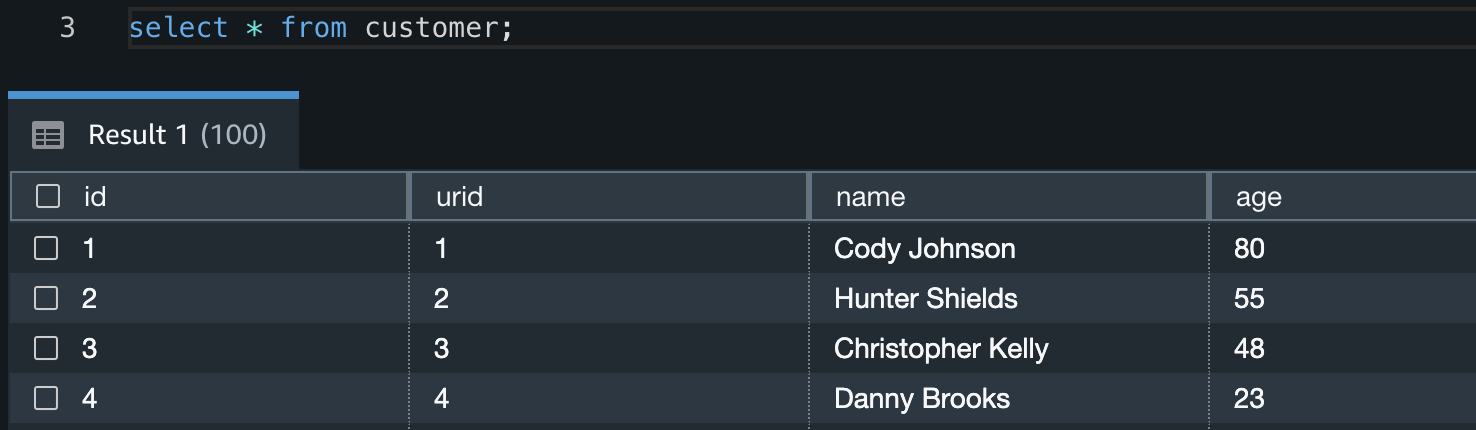
When the process has accomplished its run, you possibly can establish what duplicate prospects got distinctive IDs by working the next question:

From this you possibly can see that IDs 1, 101, and 121 have all been given the identical URID, as have IDs 7 and 107.
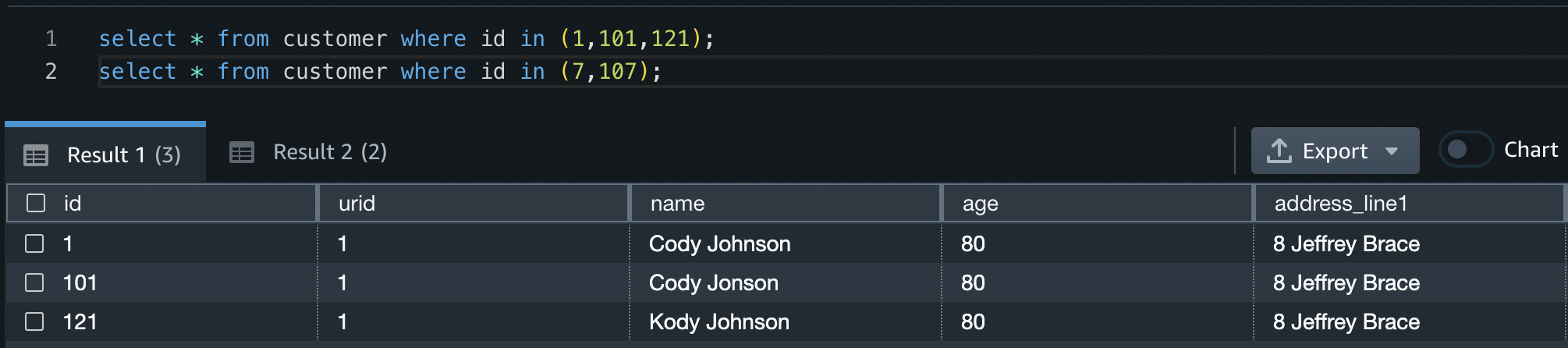
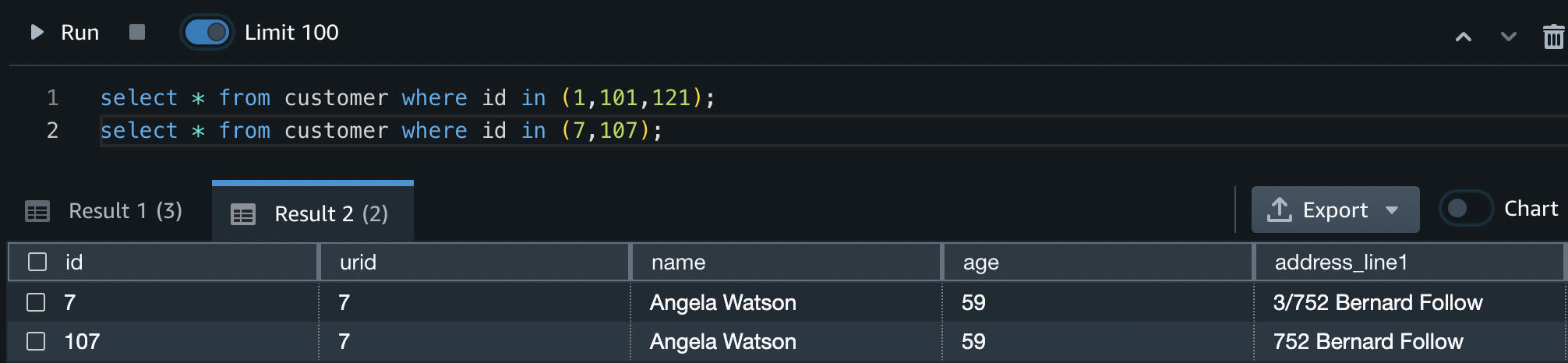
The process has additionally accurately recognized that IDs 6 and 106 are totally different prospects, and so they due to this fact don’t have the identical URID.

Clear up
To keep away from incurring future reoccurring fees, delete all recordsdata within the S3 bucket you created. After you delete the recordsdata, go to the AWS CloudFormation console and delete the stack deployed on this publish. This may delete all created assets.
Conclusion
On this publish, we confirmed one strategy to figuring out imperfect duplicate information by making use of a fuzzy matching algorithm in Amazon Redshift. This resolution permits you to establish information high quality points and apply extra correct analytics to your dataset residing in Amazon Redshift.
We confirmed how you need to use open-source Python libraries to create Python UDFs, and the way to create a generic saved process to establish imperfect matches. This resolution is extendable to offer any performance required, together with including as a daily course of in your ELT (extract, load, and remodel) workloads.
Check the created process in your datasets to research the presence of any imperfect duplicates, and use the data realized all through this publish to create saved procedures and UDFs to implement additional performance.
In the event you’re new to Amazon Redshift, check with Getting began with Amazon Redshift for extra data and tutorials on Amazon Redshift. It’s also possible to check with the video Get began with Amazon Redshift Serverless for data on beginning with Redshift Serverless.
In regards to the Creator

Sean Beath is an Analytics Options Architect at Amazon Net Providers. He has expertise within the full supply lifecycle of knowledge platform modernisation utilizing AWS providers and works with prospects to assist drive analytics worth on AWS.





