
LOANS are the most important requirement of the fashionable world. By this solely, Banks get a serious a part of the overall revenue. It’s useful for college students to handle their schooling and residing bills, and for individuals to purchase any sort of luxurious like homes, vehicles, and so forth.
However in terms of deciding whether or not the applicant’s profile is related to be granted with mortgage or not. Banks must take care of many facets.
So, right here we might be utilizing Machine Studying with Python to ease their work and predict whether or not the candidate’s profile is related or not utilizing key options like Marital Standing, Schooling, Applicant Earnings, Credit score Historical past, and so forth.
Mortgage Approval Prediction utilizing Machine Studying
You possibly can obtain the used knowledge by visiting this hyperlink.
The dataset comprises 13 options :
| 1 | Mortgage | A singular id |
|---|---|---|
| 2 | Gender | Gender of the applicant Male/feminine |
| 3 | Married | Marital Standing of the applicant, values might be Sure/ No |
| 4 | Dependents | It tells whether or not the applicant has any dependents or not. |
| 5 | Schooling | It’ll inform us whether or not the applicant is Graduated or not. |
| 6 | Self_Employed | This defines that the applicant is self-employed i.e. Sure/ No |
| 7 | ApplicantIncome | Applicant earnings |
| 8 | CoapplicantIncome | Co-applicant earnings |
| 9 | LoanAmount | Mortgage quantity (in hundreds) |
| 10 | Loan_Amount_Term | Phrases of mortgage (in months) |
| 11 | Credit_History | Credit score historical past of particular person’s reimbursement of their money owed |
| 12 | Property_Area | Space of property i.e. Rural/City/Semi-urban |
| 13 | Loan_Status | Standing of Mortgage Permitted or not i.e. Y- Sure, N-No |
Importing Libraries and Dataset
Firstly we’ve to import libraries :
- Pandas – To load the Dataframe
- Matplotlib – To visualise the info options i.e. barplot
- Seaborn – To see the correlation between options utilizing heatmap
Python3
|
|
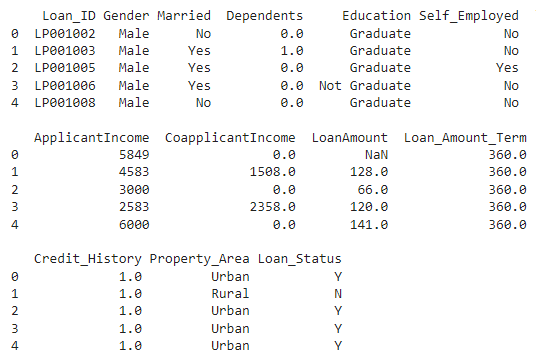
As soon as we imported the dataset, let’s view it utilizing the under command.
Output:
Information Preprocessing and Visualization
Get the variety of columns of object datatype.
Python3
|
|
Output :
Categorical variables: 7
As Loan_ID is totally distinctive and never correlated with any of the opposite column, So we’ll drop it utilizing .drop() perform.
Python3
|
|
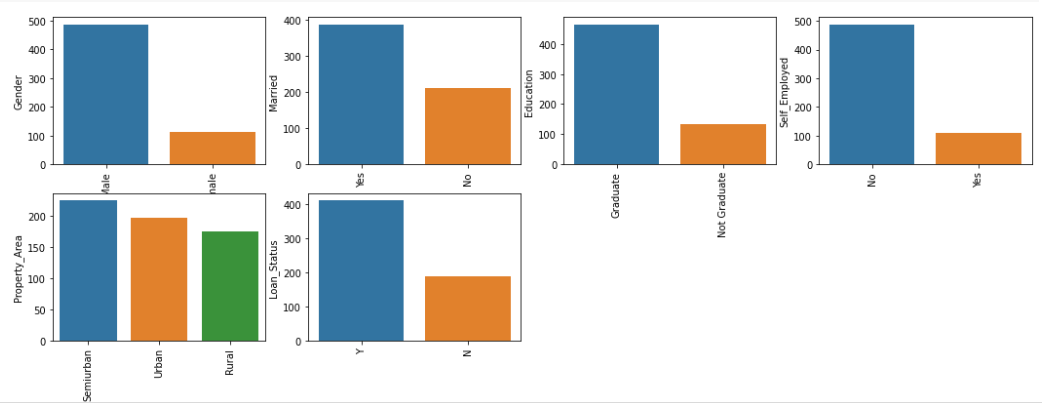
Visualize all of the distinctive values in columns utilizing barplot. This may merely present which worth is dominating as per our dataset.
Python3
|
|
Output:
As all the explicit values are binary so we will use Label Encoder for all such columns and the values will develop into int datatype.
Python3
|
|
Once more verify the item datatype columns. Let’s discover out if there’s nonetheless any left.
Python3
|
|
Output :
Categorical variables: 0
Python3
|
|
Output:
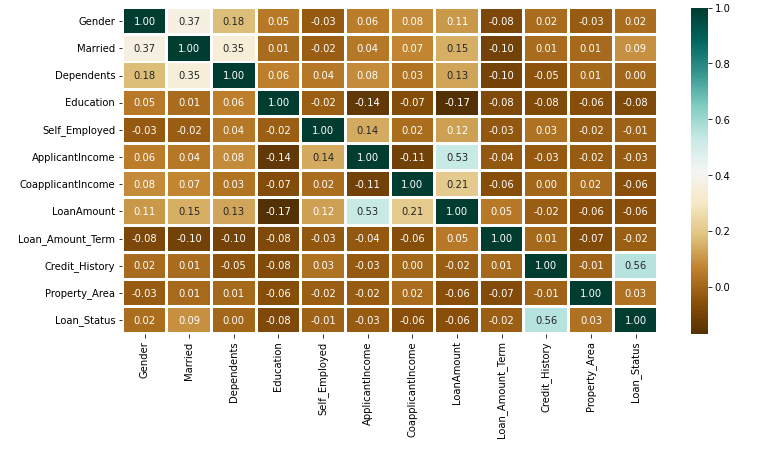
The above heatmap is displaying the correlation between Mortgage Quantity and ApplicantIncome. It additionally exhibits that Credit_History has a excessive influence on Loan_Status.
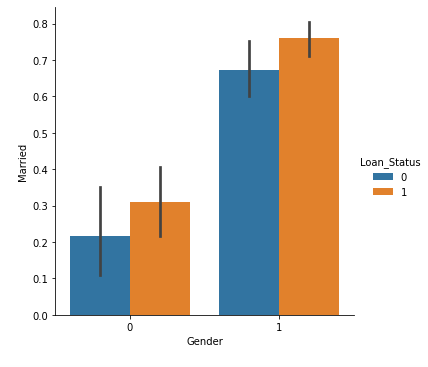
Now we’ll use Catplot to visualise the plot for the Gender, and Marital Standing of the applicant.
Python3
|
|
Output:
Now we’ll discover out if there’s any lacking values within the dataset utilizing under code.
Python3
|
|
Output:
Gender 0 Married 0 Dependents 0 Schooling 0 Self_Employed 0 ApplicantIncome 0 CoapplicantIncome 0 LoanAmount 0 Loan_Amount_Term 0 Credit_History 0 Property_Area 0 Loan_Status 0
As there is no such thing as a lacking worth then we should proceed to mannequin coaching.
Splitting Dataset
Python3
|
|
Output:
((598, 11), (598,)) ((358, 11), (240, 11), (358,), (240,))
Mannequin Coaching and Analysis
As this can be a classification drawback so we might be utilizing these fashions :
To foretell the accuracy we’ll use the accuracy rating perform from scikit-learn library.
Python3
|
|
Output :
Accuracy rating of RandomForestClassifier = 98.04469273743017
Accuracy rating of KNeighborsClassifier = 78.49162011173185
Accuracy rating of SVC = 68.71508379888269
Accuracy rating of LogisticRegression = 80.44692737430168
Prediction on the take a look at set:
Python3
|
|
Output :
Accuracy rating of RandomForestClassifier = 82.5
Accuracy rating of KNeighborsClassifier = 63.74999999999999
Accuracy rating of SVC = 69.16666666666667
Accuracy rating of LogisticRegression = 80.83333333333333
Conclusion :
Random Forest Classifier is giving the very best accuracy with an accuracy rating of 82% for the testing dataset. And to get a lot better outcomes ensemble studying methods like Bagging and Boosting may also be used.
